大数据Shuffle原理与实践
2025年2月22日大约 3 分钟
Shuffle概述
MapReduce概述
- 阶段:Map、Shuffle、Reduce
Map阶段
单机上,针对一小块数据的计算过程
Shuffle阶段
在map阶段的基础上,进行数据移动,为后续的reduce阶段做准备。 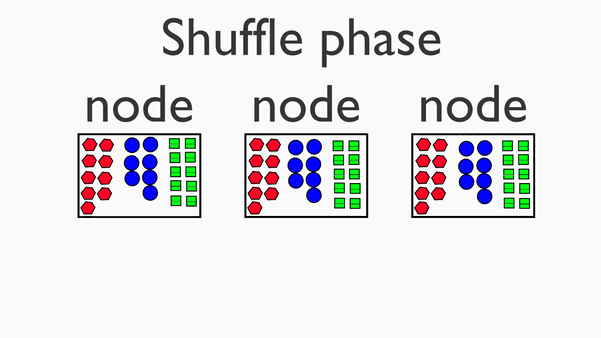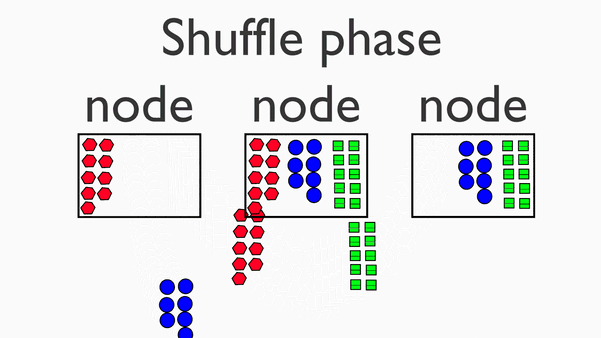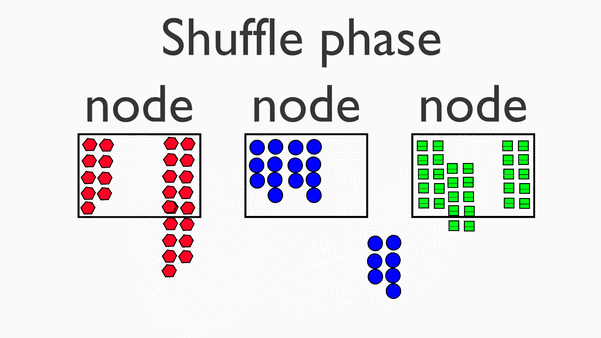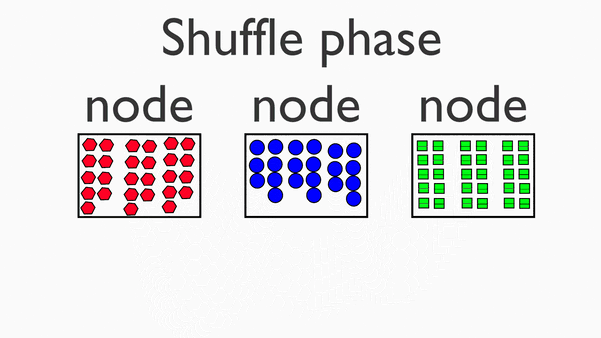
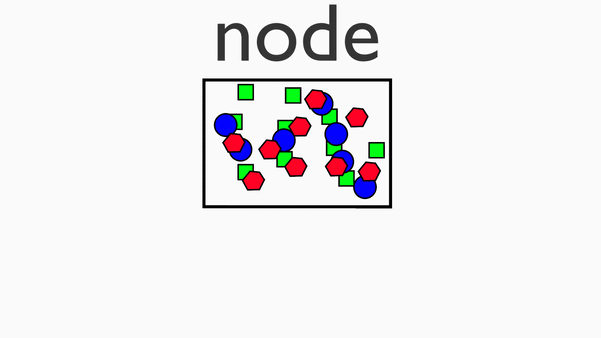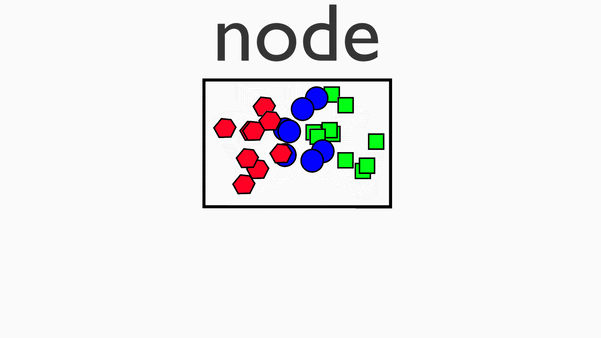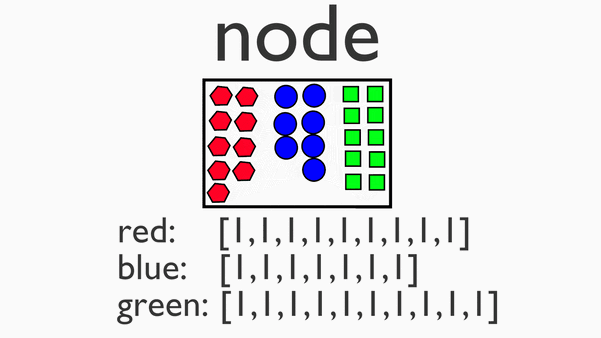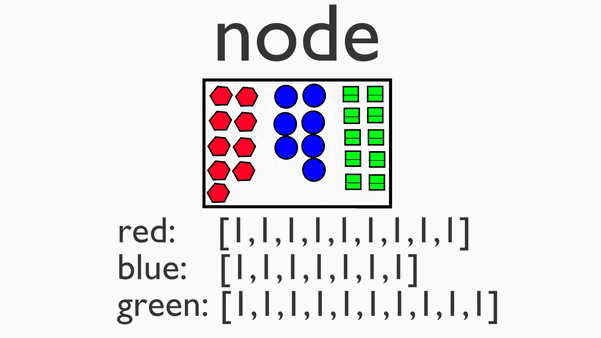
Reduce阶段
reduce阶段,对移动后的数据进行处理,依然是在单机上处理一小份数据 
Shuffle阶段为什么对性能非常重要
- M * R次网络连接
- 大量的数据移动
- 数据丢失风险
- 可能存在大量的排序操作
- 大量的数据序列化,反序列化操作
- 数据压缩
小结
在大数据场景下,数据shuffle表示了不同分区数据交换的过程,不同的shuffle策略性能差异较大。 目前在各个引擎中shuffle都是优化的重点,在spark框架中,shuffle是支撑spark进行大规模复杂数据处理的基石。
Shuffle算子
Spark中会产生shuffle的算子大概分为四类
| repartition | ByKey | join | Distinct |
|---|---|---|---|
| coalesce | groupByKey | cogroup | distinct |
| repartition | reduceByKey | join | |
| aggregateByKey | leftOuterJoin | ||
| combineByKey | intersection | ||
| sortByKey | subtract | ||
| sortBy | subtractByKey |
Shuffle算子应用
val text = sc.textFile("mytextfile.txt")
val counts = text
.flatMap(line => line.split(" "))
.map(word => (word,1))
.reduceByKey(_+_)
counts.collectSpark对Shuffle的抽象
- 窄依赖:父RDD的每个分片至多被子 RDD中的一个分片所依赖
- 宽依赖:父RDD中的分片可能被子 RDD中的多个分片所依赖
算子内部的依赖关系
- Shuffle Dependency
- 创建会产生shuffle的RDD时,RDD会创建Shuffle Dependency来描述Shuffle相关的信息
- 构造函数
- A single key-value pair RDD, i.e. RDD[Product2[K, V]],
- Partitioner (available as partitioner property),
- Serializer,
- Optional key ordering (of Scala’s scala.math.Ordering type),
- Optional Aggregator,
- mapSideCombine flag which is disabled (i.e. false) by default.
- Partitioner
- 用来将record映射到具体的partition的方法
- 接口
- numberPartitions
- getPartition
- Aggregator
- 在map侧合并部分record的函数
- 接口
- createCombiner:只有一个value的时候初始化的方法
- mergeValue:合并一个value到Aggregator中
- mergeCombiners:合并两个Aggregator
Shuffle过程
spark中的shuffle变迁过程
- HashShuffle
- 优点:不需要排序
- 缺点:打开,创建的文件过多
- SortShuffle
- 优点:打开的文件少、支持map-side combine
- 缺点:需要排序
- TungstenSortShuffle
- 优点:更快的排序效率,更高的内存利用效率
- 缺点:不支持map-side combine
Register Shuffle
- 由action算子触发DAG Scheduler进行shuffle register
- Shuffle Register会根据不同的条件决定注册不同的ShuffleHandle
Shuffle参数优化
- spark.default.parallelism && spark.sql.shuffle.partitions
- spark.hadoopRDD.ignoreEmptySplits
- spark.hadoop.mapreduce.input.fileinputformat.split.minsize
- spark.sql.file.maxPartitionBytes
- spark.sql.adaptive.enabled && spark.sql.adaptive.shuffle.targetPostShuffleInputSize
- spark.reducer.maxSizeInFlight
- spark.reducer.maxReqsInFlight
- spark.reducer.maxBlocksInFlightPerAddress
Shuffle倾斜优化
- 倾斜影响
- 作业运行时间变长
- Task OOM导致作业失败
常见地倾斜处理办法
- 提高并行度
- 优点:足够简单
- 缺点: 只缓解、不根治
- AQE Skew Join
- AQE根据shuffle文件统计数据自动检测倾斜数据,将那些倾斜的分区打散成小的子分区,然后各自进行join。
Push Shuffle
- 上一部分所讲的shuffle过程存在哪些问题?
- 数据存储在本地磁盘,没有备份
- IO 并发:大量 RPC 请求(M*R)
- IO 吞吐:随机读、写放大(3X)
- GC 频繁,影响 NodeManager
- 为了优化该问题,有很多公司都做了思路相近地优化,push shuffle
- Magnet主要流程 主要为边写边push的模式,在原有的shuffle基础上尝试push聚合数据,但并不强制完成,读取时优先读取push聚合的结果,对于没有来得及完成聚合或者聚合失败的情况,则fallback到原模式。