流式计算中的window机制
概述
流式计算 vs 批式计算
数据价值:实时性越高,数据价值越高
| 特性 | 批式计算 | 流式计算 |
|---|---|---|
| 数据存储 | HDFS、Hive | Kafka、Pulsar |
| 数据时效性 | 天级别 | 分钟级别 |
| 准确性 | 精准 | 精准和时效性之间取舍 |
| 经典计算引擎 | Hive、Spark、Flink | Flink |
| 计算模型 | Exactly-Once | At Least Once/Exactly Once |
| 资源模型 | 定时调度 | 长期持有 |
| 主要场景 | 离线天级别数据报表 | 实时数仓、实时营销、实时风控 |
批处理
批处理模型典型的数仓架构为T+1架构,即数据计算时天级别的,当天只能看到前一天的计算结果。 通常使用的计算引擎为Hive或者Spark等。计算的时候,数据是完全ready的,输入和输出都是确定性的。
处理时间窗口
实时计算:处理时间窗口 数据实时流动,实时计算,窗口结束直接发送结果,不需要周期调度任务。 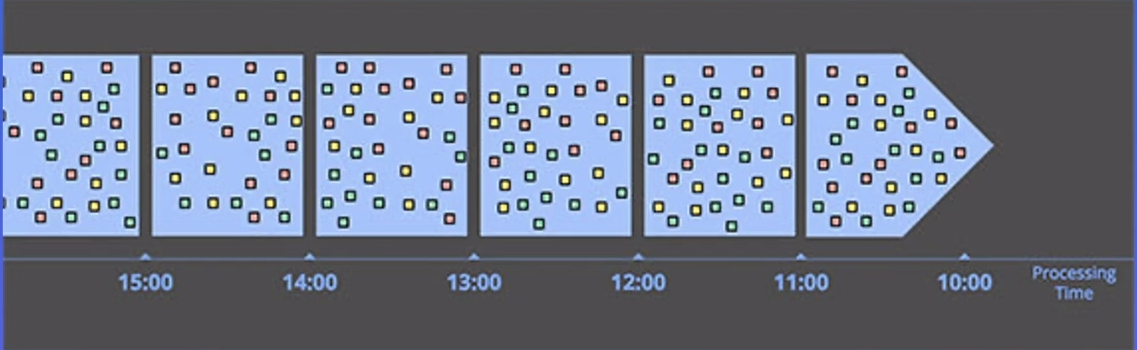
处理时间 vs 事件时间
处理时间:数据在流式计算系统中真正处理时所在机 器的当前时间。 事件时间:数据产生的时间,比如客户端、传感器、 后端代码等上报数据时的时间。
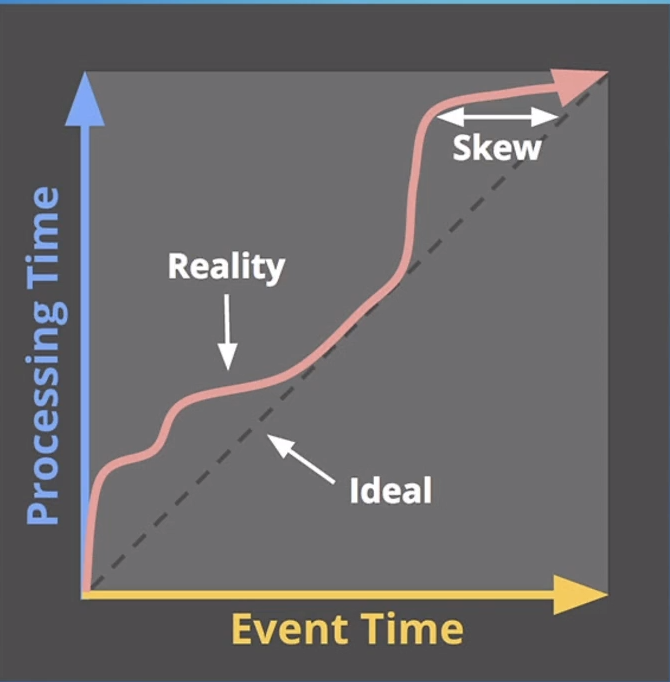
通常情况下,处理时间与事件时间相比会有延迟(处理需要时间)
事件时间窗口
实时计算:事件时间窗口 数据实时进入到真实事件发生的窗口中进行计算,可以有效的处理数据延迟和乱序。
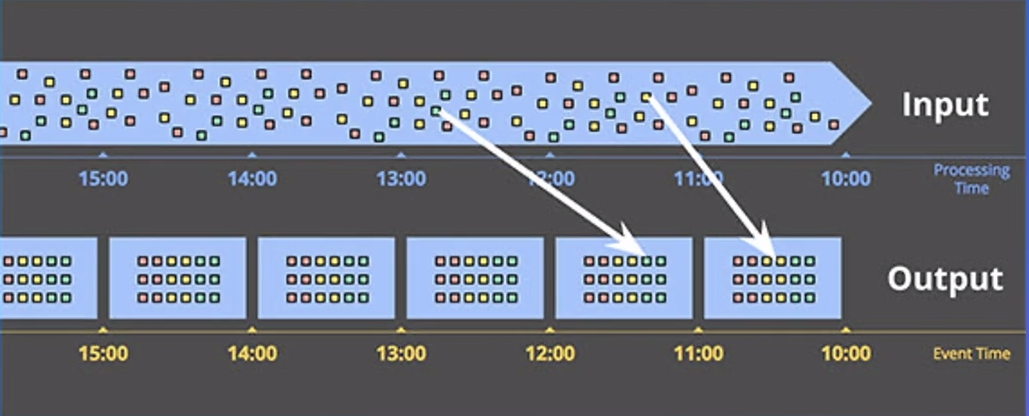
WaterMark
在数据中插入一些watermark,来表示当前的真实时间。 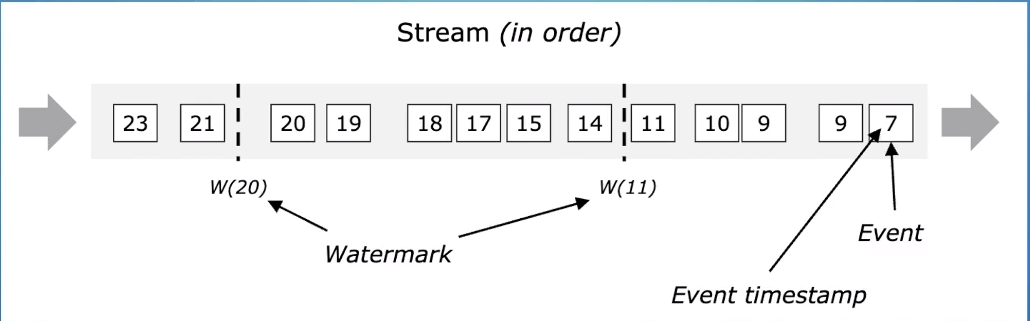 在数据存在乱序的时候,watermark就比较重要了,它可以用来在乱序容忍和实时性之间做一个平衡。
在数据存在乱序的时候,watermark就比较重要了,它可以用来在乱序容忍和实时性之间做一个平衡。 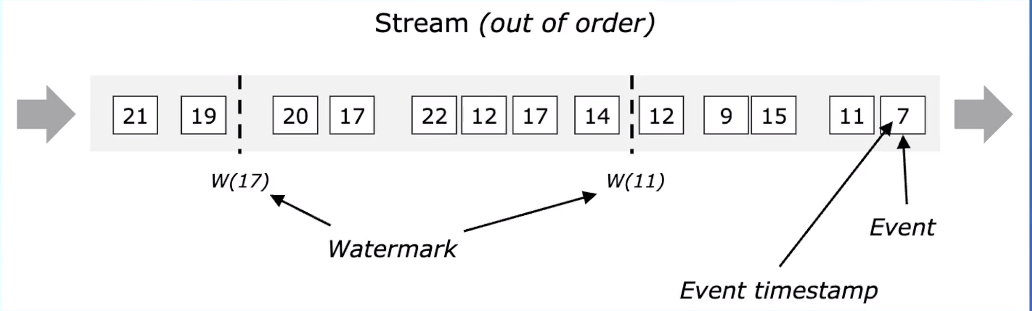
Watermark
定义:表示系统认为的当前真实的事件时间
Watermark产生:一般是从数据的事件时间来产生,产生策略可以灵活多样,最常见的包括使用当前事件时间的时间减去一个固定的delay,来表示可以可以容忍多长时间的乱序。

Watermark传递:这个类似于上节课中介绍的Checkpoint的制作过程,传递就类似于Checkpoint的barrier,上下游task之间有数据传输关系的,上游就会将watermark传递给下游;下游收到多个上游传递过来的watermark后,默认会取其中最小值来作为自身的watermark,同时它也会将自己watermark传递给它的下游。经过整个传递过程,最终系统中每一个计算单元就都会实时的知道自身当前的watermark是多少。
怎么观察一个任务中的watermark是多少,是否是正常的
- 一般通过Flink Web UI上的信息来观察当前任务的watermark情况
- 这个问题是生产实践中最容易遇到的问题,大家在开发事件时间的窗口任务的时候,经常会忘记了设置watermark,或者数据太少,watermark没有及时的更新,导致窗口一直不能触发。
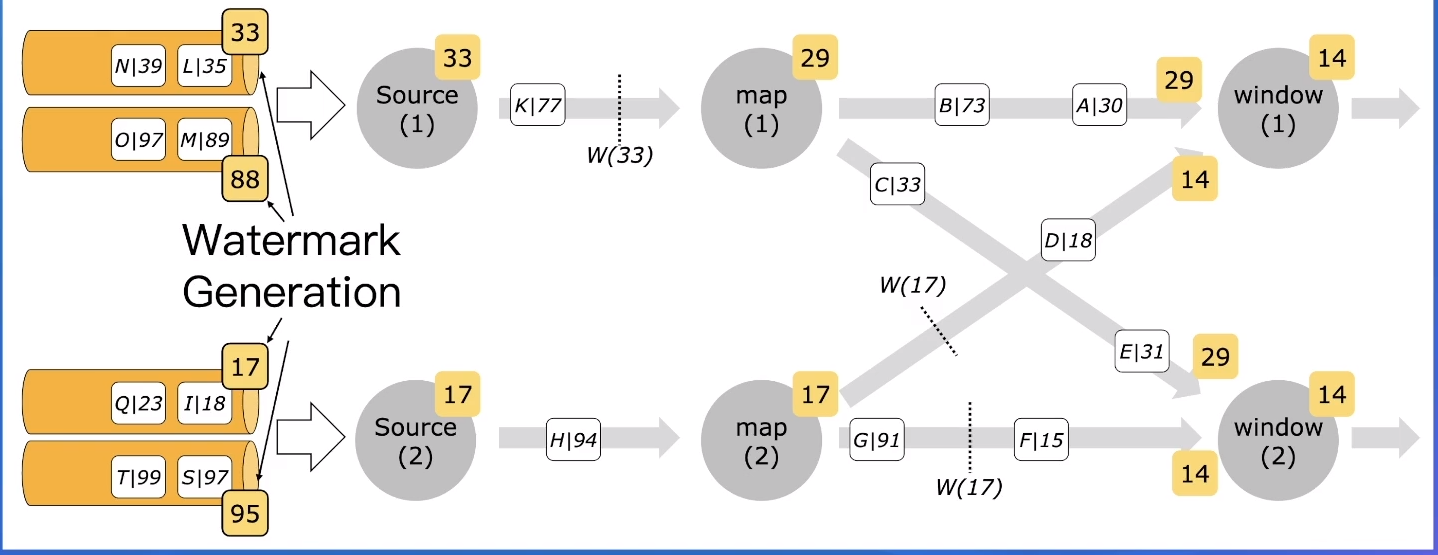
Per-partition / Per-subtask 生成watermark的优缺点
- 在Flink里早期都是per-subtask的方式进行watermark的生成,这种方式比较简单。但是如果每个source task如果有消费多个partition的情况的话,那多个partition之间的数据可能会因为消费的速度不同而最终导致数据的乱序程度增加。
- 后期(上面图中)就逐步的变成了per-partition的方式来产生watermark,来避免上面的问题。
如果有部分partition/subtask会断流,应该如何处理
- 数据断流是很常见的问题,有时候是业务数据本身就有这种特点,比如白天有数据,晚上没有数据。在这种情况下,watermark默认是不会更新的,因为它要取上游subtask发来的watermark中的最小值。此时我们可以用一种IDLE状态来标记这种subtask,被标记为这种状态的subtask,我们在计算watermark的时候,可以把它先排除在外。这样就可以保证有部分partition断流的时候,watermark仍然可以继续更新。
算子对于时间晚于watermark的数据的处理
- 对于迟到数据,不同的算子对于这种情况的处理可以有不同的实现(主要是根据算子本身的语义来决定的)
- 比如window对于迟到的数据,默认就是丢弃;比如双流join,对于迟到数据,可以认为是无法与之前正常数据join上。
window
- 使用:
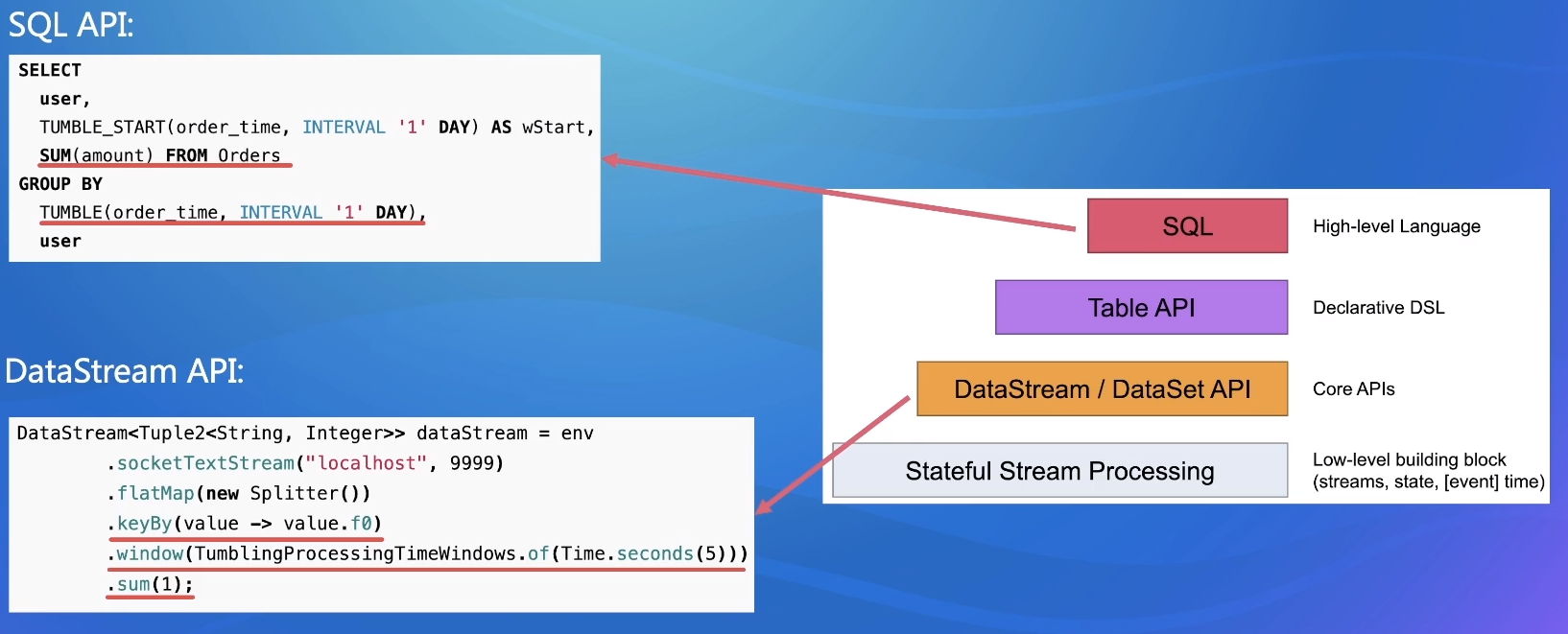 窗口划分:
窗口划分:
- 每个key单独划分
- 每条数据只会属于一个窗口 窗口触发: Window结束时间到达的时候一次性触发
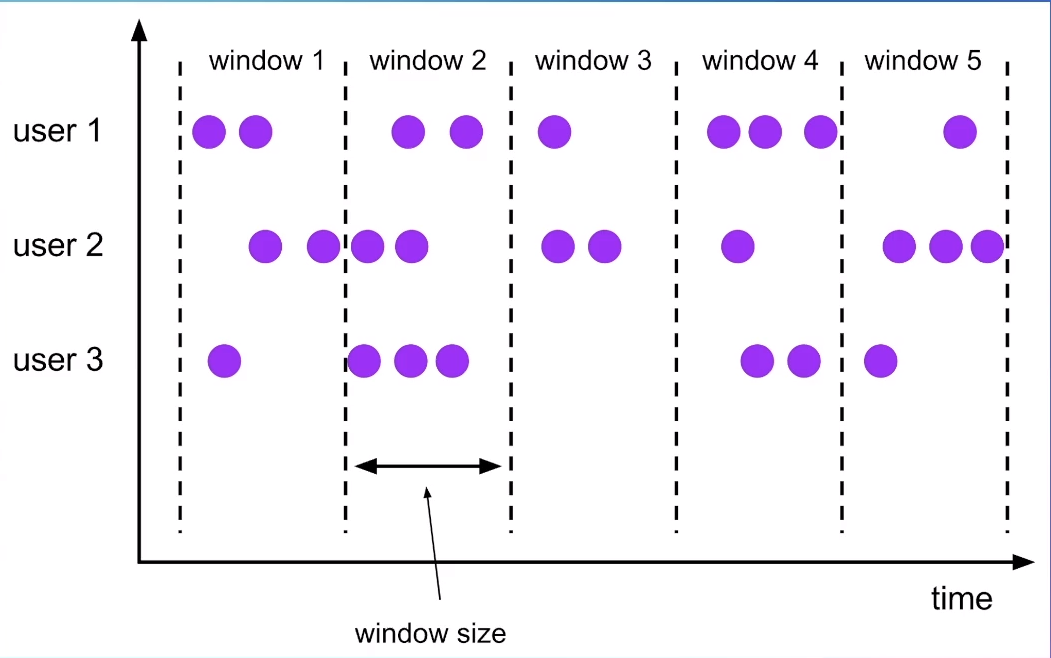
TUMBLE Window(滚动窗口)
这是最常见的窗口类型,就是根据数据的时间(可以是处理时间,也可以是事件时间)划分到它所属的窗口中windowStart = timestamp - timestamp % windowSize,这条数据所属的window就是[windowStart, windowStart + windowSize)
在我们使用window的过程中,最容易产生的一个疑问是,window的划分是subtask级别的,还是key级别的。这里大家要记住,Flink 中的窗口划分是key级别的。 比如下方的图中,有三个key,那每个key的窗口都是单独的。所以整个图中,一种存在14个窗口。
窗口的触发,是时间大于等于window end的时候,触发对应的window的输出(计算有可能提前就增量计算好了),目前的实现是给每个window都注册一个timer,通过处理时间或者事件时间的timer来触发window的输出。
HOP Window(滑动窗口)
一条数据可能属于多个窗口 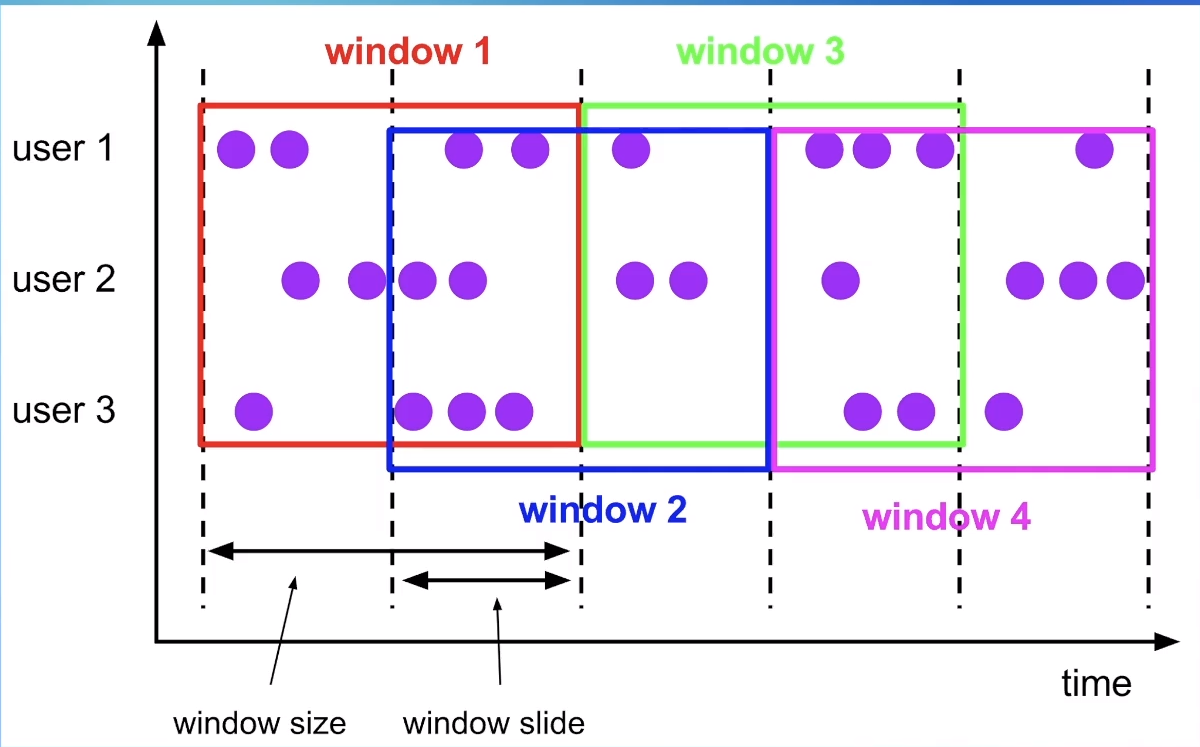
SESSION Window(会话窗口)
会话窗口跟上面两种窗口区别比较大,上面两个窗口的划分,都是根据当前数据的时间就可以直接确定它所属的窗口。会话窗口的话,是一个动态merge的过程。一般会设置一个会话的最大的gap,比如10min。
那某个key下面来第一条数据的时候,它的window就是 (event_time, event_time + gap),当这个key后面来了另一条数据的时候,它会立即产生一个窗口,如果这个窗口跟之前的窗口有overlap的话,则会将两个窗口进行一个merge,变成一个更大的窗口,此时需要将之前定义的timer取消,再注册一个新的timer。
所以会话窗口要求所有的聚合函数都必须有实现merge。 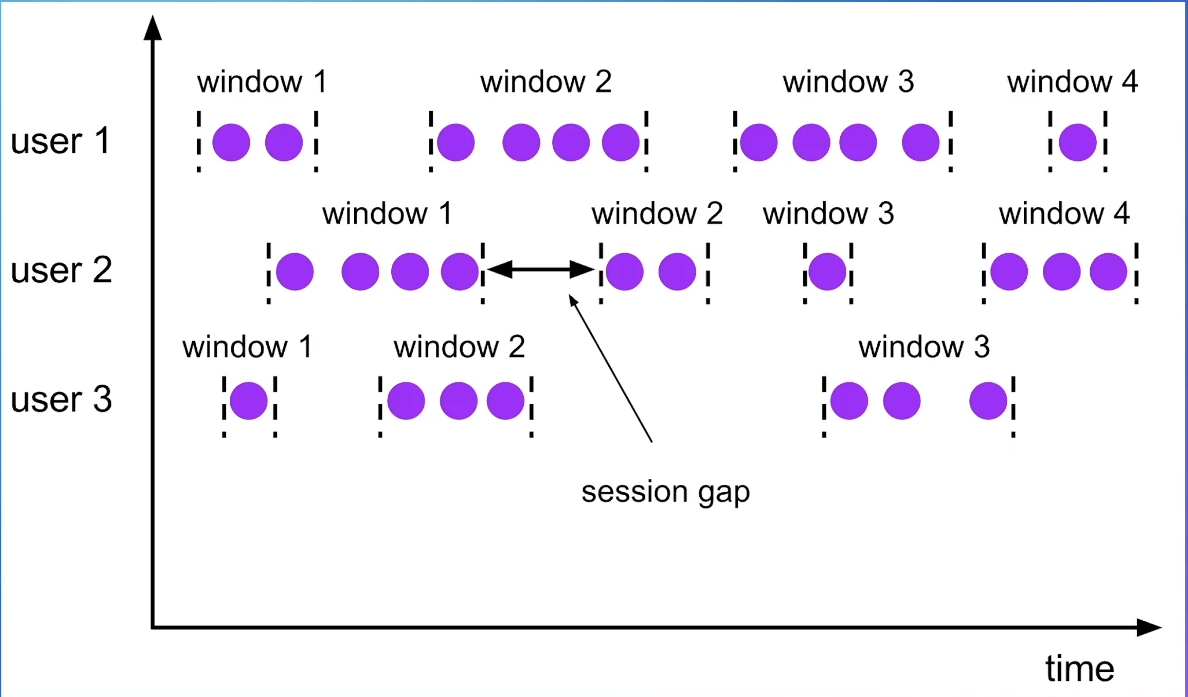
迟到数据处理
根据上面说到的watermark原理,watermark驱动某个窗口触发输出之后,这个窗口如果后面又来了数据,那这种情况就属于是迟到的数据了。(注意,不是数据的时间晚于watermark就算是迟到,而是它所属的窗口已经被触发了,才算迟到)。
对于迟到的数据,我们现在有两种处理方式:
- side output(侧输出流)
- 使用side output(侧输出流)方式,把迟到的数据转变成一 个单独的流,再由用户自己来决定如何处理这部分数据
- Allow lateness:
- 这种方式需要设置一个允许迟到的时间。设置之后,窗口正常计算结束后,不会马上清理状态,而是会多保留allowLateness这么长时间,在这段时间内如果还有数据到来,则继续之前的状态进行计算。
- 适用于:DataStream、SQL
- 直接drop掉 注意:side output只有在DataStream的窗口中才可以用,在SQL中目前还没有这种语义,所以暂时只有drop这一个策略。
增量计算 vs 全量计算
- 增量计算:
- 每条数据到来,直接进行计算,window.只存储计算结果。比如计算sum,状态中只需要存储sum的结果,不需要保存每条数据。
- 典型的reduce、aggregate等函数都是增量计算
- SQL中的聚合只有增量计算
- 全量计算:
- 每条数据到来,会存储到window的state中。等到window触发计算的时候,将所有数据拿出来一起计算。
- 典型的processl函数就是全量计算
EMIT触发
上面讲到,正常的窗口都是窗口结束的时候才会进行输出,比如一个1天的窗口,只有到每天结束的时候,窗口的结果才会输出。这种情况下就失去了实时计算的意义了。 那么EMIT触发就是在这种情况下,可以提前把窗口内容输出出来的一种机制。比如我们可以配置一个1天的窗口,每隔5s输出一次它的最新结果,那这样下游就可以更快的获取到窗口计算的结果了。 这个功能只在SQL中,如果是在DataStream中需要完成类似的功能,需要自己定义一些trigger来做。 上节课中,有讲到retract机制,这里需要提一下,这种emit的场景就是一个典型的retract的场景,发送的结果类似于+[1], -[1], +[2], -[2], +[4]这样子。这样才能保证window的输出的最终结果是符合语义的。
- SQL实现:
- table.exec.emit.early-fire.enabled=true
- table.exec.emit.early-fire.delay={time)
高级优化
Mini-batch优化
一般来讲,Flink的状态比较大一些都推荐使用rocksdb statebackend,这种情况下,每次的状态访问就都需要做一次序列化和反序列化,这种开销还是挺大的。为了降低这种开销,我们可以通过降低状态访问频率的方式来解决,这就是mini-batch最主要解决的问题:即赞一小批数据再进行计算,这批数据每个key的state访问只有一次,这样在单个key的数据比较集中的情况下,对于状态访问可以有效的降低频率,最终提升性能。
这个优化主要是适用于没有窗口的聚合场景,字节内部也扩展了window来支持mini-batch,在某些场景下的测试结果可以节省20-30%的CPU开销。
mini-batch看似简单,实际上设计非常巧妙。假设用最简单的方式实现,那就是每个算子内部自己进行攒一个小的batch,这样的话,如果上下游串联的算子比较多,任务整体的延迟就不是很容易控制。所以真正的mini-batch实现,是复用了底层的watermark传输机制,通过watermark事件来作为mini-batch划分的依据,这样整个任务中不管串联的多少个算子,整个任务的延迟都是一样的,就是用户配置的delay时间。
下面这张图展示的是普通的聚合算子的mini-batch原理,window的mini-batch原理是一样的。 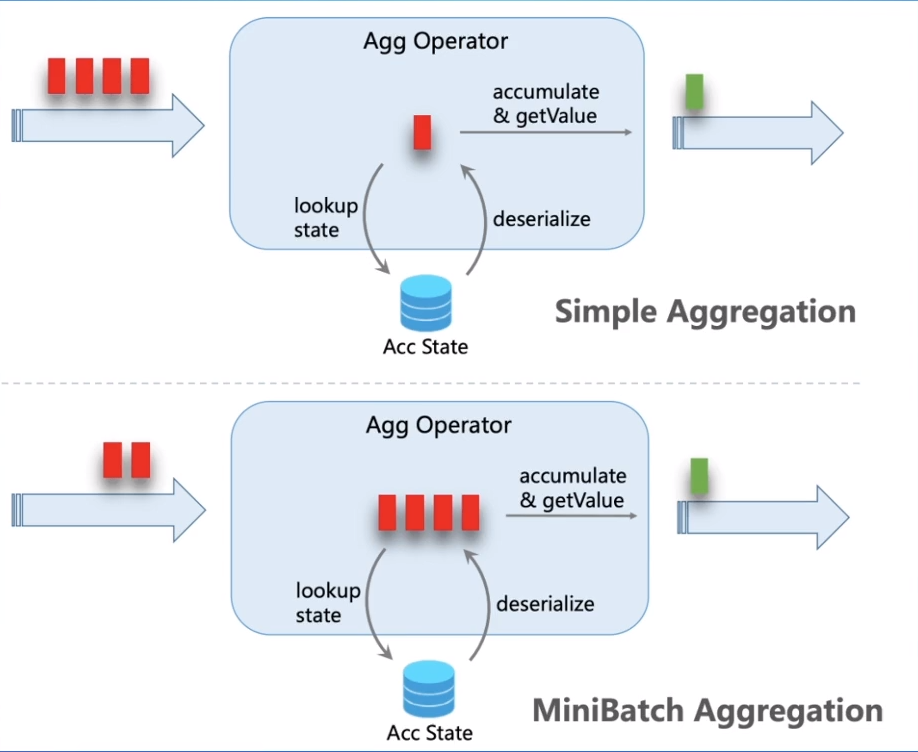
倾斜优化-local-global
local-global优化是分布式系统中典型的优化,主要是可以降低数据shuffle的量,同时也可以缓解数据的倾斜。
所谓的local-global,就是将原本的聚合划分成两阶段,第一阶段先做一个local的聚合,这个阶段不需要数据shuffle,是直接跟在上游算子之后进行处理的;第二个阶段是要对第一个阶段的结果做一个merge(还记得上面说的session window的merge么,这里要求是一样的。如果存在没有实现merge的聚合函数,那么这个优化就不会生效)。
如下图所示,比如是要对数据做一个sum,同样颜色的数据表示相同的group by的key,这样我们可以再local agg阶段对他们做一个预聚合;然后到了global阶段数据倾斜就消除了。
Distinct计算状态复用
对于distinct的优化,一般批里面的引擎都是通过把它优化成aggregate的方式来处理,但是在流式window中,我们不能直接这样进行优化,要不然算子就变成会下发retract的数据了。所以在流式中,对于count distinct这种情况,我们是需要保存所有数据是否出现过这样子的一个映射。
在SQL中,我们有一种方式可以在聚合函数上添加一些filter,如下面的SQL所示: 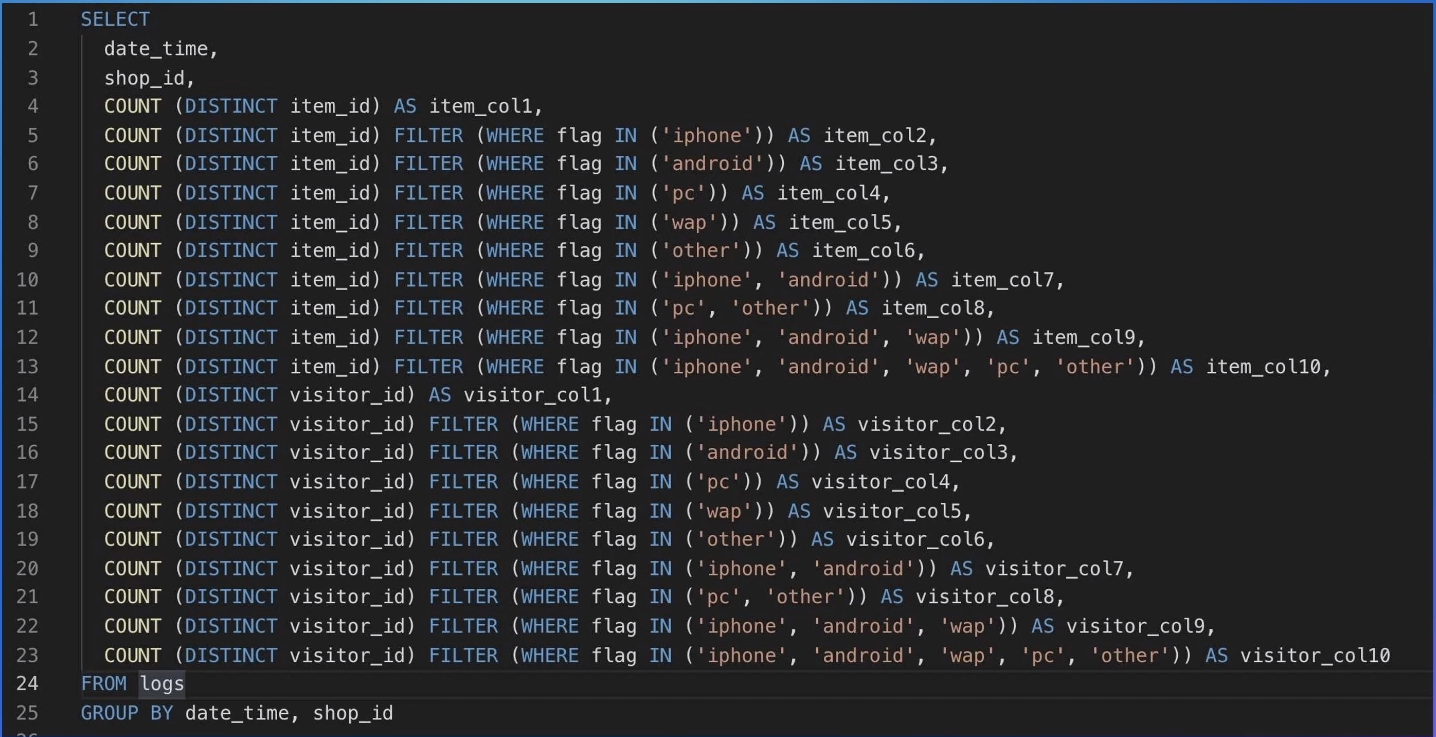 像这种情况,我们会对同一个字段用不同的filter来进行count distinct的计算。如果每个指标都单独用一个map来记录每条数据是否出现过,那状态量是很大的。
像这种情况,我们会对同一个字段用不同的filter来进行count distinct的计算。如果每个指标都单独用一个map来记录每条数据是否出现过,那状态量是很大的。
我们可以把相同字段的distinct计算用一个map的key来存储,在map的value中,用一个bit vector来实现就可以把各个状态复用到一起了。比如一个bigint有64位,可以表示同一个字段的64个filter,这样整体状态量就可以节省很多了。 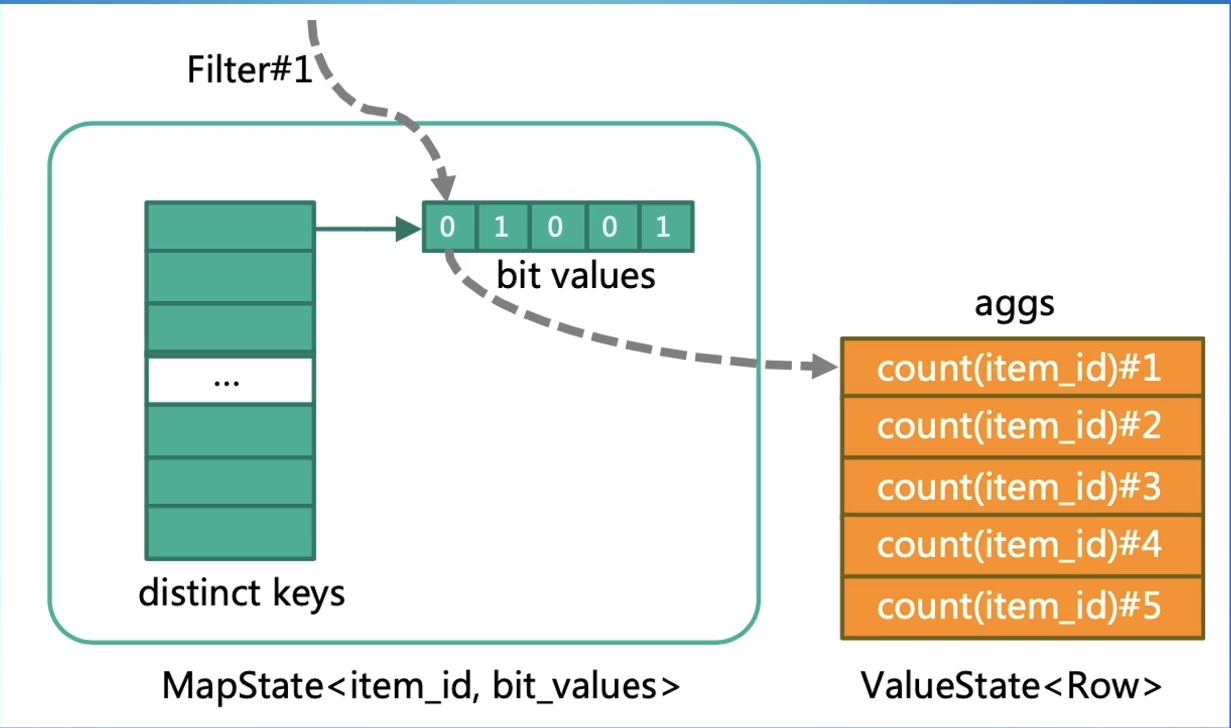
滑动窗口pane复用
滑动窗口如上面所述,一条数据可能会属于多个window。所以这种情况下同一个key下的window数量可能会比较多,比如3个小时的窗口,1小时的滑动的话,每条数据到来会直接对着3个窗口进行计算和更新。这样对于状态访问频率是比较高的,而且计算量也会增加很多。
优化方法就是,将窗口的状态划分成更小粒度的pane,比如上面3小时窗口、1小时滑动的情况,可以把pane设置为1h,这样每来一条数据,我们就只更新这条数据对应的pane的结果就可以了。当窗口需要输出结果的时候,只需要将这个窗口对应的pane的结果merge起来就可以了。
注意:这里也是需要所有聚合函数都有merge的实现的 
案例分析
计算实时抖音DAU曲线
DAU:指的是每天的去重活跃用户数 输出:每个5s更新一下当前的DAU数值,最终获得一天内的DAU变化曲线 要求:通过上面课程中学到的窗口的功能以及相关的优化,开发一个Flink SQL任务,使得可以高效的计算出来上面要求的实时结果。
问题:所有数据都需要在一个subtask中完成窗口计算,无法并行

分桶
- 思路:通过两阶段聚合来把数据打散,完成第一轮聚合,第二轮聚合只需要对各个分桶的结果求和即可。

- 思路:通过两阶段聚合来把数据打散,完成第一轮聚合,第二轮聚合只需要对各个分桶的结果求和即可。
计算大数据任务的资源使用
问题描述:大数据任务(特指离线任务)运行时通常会有多个container启动并运行,每个containeri在运行结束的时候,YARN会负责将它的资源使用(CPU、内存)情况上报。一般大数据任务运行时间从几分钟到几小时不等。
需求:根据YARN上报的各个container的信息,在任务结束的时候,尽快的计算出一个任务运行所消耗的总的资源。
假设前后两个container结束时间差不超过l0min(会话窗口间隔时间)
思路:通过会话窗口将数据划分到一个window中,然后再将结果求和即可。
