Flink
2025年2月22日大约 10 分钟
Flink简介
基本概念
Apache Flink是一个开源的流处理框架,应用于分布式、高性能、高可用的数据流应用程序。可以处理有限数据流和无限数据,即能够处理有边界和无边界的数据流。无边界的数据流就是真正意义上的流数据,所以Flink是支持流计算的。有边界的数据流就是批数据,所以也支持批处理的。不过Flink在流处理上的应用比在批处理上的应用更加广泛,统一批处理和流处理也是Flink目标之一。Flink可以部署在各种集群环境,可以对各种大小规模的数据进行快速计算。
大数据(Big Data):指无法在一定时间内用常规软件工具对其进行获取、存储、管理和处理的数据集合. - 价值化:价值密度低、整体价值高 - 海量化:数据总量大 - 快速化:数据产生、处理的速度快 - 多样化:数据源、数据种类多(格式化、半格式化、结构化数据)
大数据计算框架发展历史

为什么需要流式计算
大数据的实时性带来价值更大
- 监控场景:如果能实时发现业务系统的健康状态,就能提前避免业务故障:
- 金融风控:如果实时监测出异常交易的行为,就能及时阻断风险的发生;
- 实时推荐:比如在抖音,如果可以根据用户的行为数据发掘用户的兴趣、偏好,就能向用户推荐更感兴趣的内容;
大数据实时性的需求,带来了大数据计算架构模式的变化
- 批示处理
流处理与批处理区别
- 期望目标:
- 低延迟
- 高吞吐
- 结果的准确性和良好的容错性
| 流式计算 | 批式计算 | |
|---|---|---|
| 个人理解 | 他人发微信实时发送,实时接收 ,更真实地反映了我们的生活方式 | 闲暇时,将之前接收到的微信消息一并查看、处理。 |
| 计算方式 | 实时计算 | 离线计算 |
| 处理时间 | 延迟在秒级以内 | 处理时间为分钟到小时级别,甚至天级别 |
| 处理延迟 | 0~1s | 10s~1h+ |
| 应用场景 | 广告推荐、金融风控 | 搜索引擎索引构建、批式数据分析 |
| 数据流 | 无限数据集 | 有限数据集 |
| 时延 | 低延迟、业务会感知运行中的情况 | 实时性要求不高,只关注最终结果产出时间 |
Flink特征
- 一切皆为流 事件驱动应用(Event-driven Applications)
- 正确性保证
- 唯一状态一致性(Exactly-once state consistency)
- 事件-事件处理(Event-time processing)
- 高超的最近数据处理(Sophisticated late data handling)
- 多层api
- 基于流式和批量数据处理的SQL(SQL on Stream & Batch Data)
- 流水数据API & 数据集API(DataStream API & DataSet API)
- 处理函数 (时间 & 状态)(ProcessFunction (Time & State))
4.易用性
- 部署灵活(Flexible deployment)
- 高可用安装(High-availability setup)
- 保存点(Savepoints)
5.可扩展性
- 可扩展架构(Scale-out architecture)
- 大量状态的支持(Support for very large state)
- 增量检查点(Incremental checkpointing)
6.高性能
- 低延迟(Low latency)
- 高吞吐量(High throughput)
- 内存计算(In-Memory computing)
Flink vs Spark
数据处理架构

- 数据模型
- Spark采用RDD模型,spark streaming 的DStream实际上也就是一组组小批数据RDD的集合
- Flink基本数据模型是数据流,以及事件(Event)序列
- 运行时架构
- spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个
- flink是标准的流执行模式,一个时间在一个节点处理完后可以直接发往下一个节点进行处理
流式计算引擎对比
| Storm | Spark Streaming | Flink | |
|---|---|---|---|
| Streaming Model | Native | mini-batch | Native |
| 一致性保证 | At Least/Most Once | Exactly-Once | Exactly-Once |
| 延迟 | 低延迟(毫秒级) | 延迟较高(秒级) | 低延迟(毫秒级) |
| 吞吐 | Low | High | High |
| 容错 | ACK | RDD Based Checkpoint | Checkpoint(Chandy-Lamport) |
| StateFul | No | Yes(DStream) | Yes(Operator) |
| SQL支持 | No | Yes | Yes |
Flink整体架构
分层架构

- SDK 层:Flink's APIs Overview;
- 执行引擎层(Runtime 层):执行引擎层提供了统一的 DAG,用来描述数据处理的 Pipeline,不管是流还是批,都会转化为 DAG 图,调度层再把 DAG 转化成分布式环境下的 Task,Task 之间通过 Shuffle 传输数据;
- 调度:Jobs and Scheduling;
- Task 生命周期:Task Lifecycle;
- Flink Failover 机制:Task Failure Recovery;
- Flink 反压概念及监控:Monitoring Back Pressure;
- Flink HA 机制:Flink HA Overview;
- 状态存储层:负责存储算子的状态信息
- 资源调度层:目前Flink可以支持部署在多种环境
核心组件
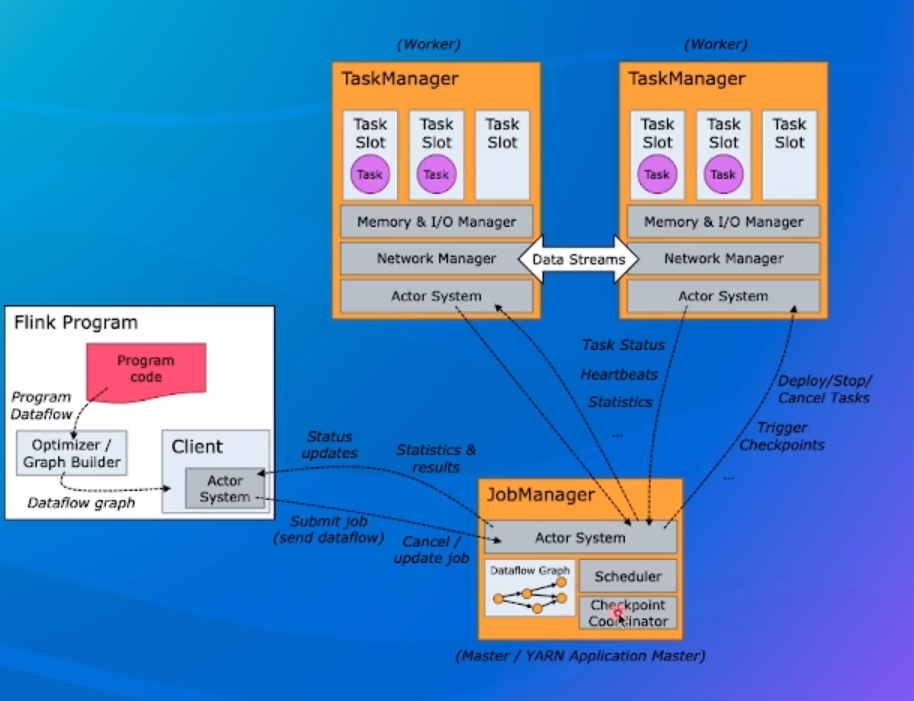 一个Flink集群,主要包含以下两个核心组件:
一个Flink集群,主要包含以下两个核心组件:
- JobManager(JM):负责整个任务的协调工作 包括:调度task、触发协调Task做Checkpoint. 协调容错恢复等;
- TaskManager(TM):负责执行一个DataFlow Graph的各个task以及data streams的buffer和 数据交换。
JobManager职责
- Dispatcher:接收作业,拉起JobManager来执行作业,并在JobMaster挂掉之后恢复作业;
- JobMaster:管理一个job的整个生命周期,会向ResourceManager申请slot,并将task调度到对应TM上;
- ResourceManager:负责slot资源的管理和调度,Task manager拉起之后会向RM注册;
Flink作业示例

Flink流批一体
为什么需要流批一体
- 流处理:在抖音中,实时统计一个短视频的播放量、点赞数 也包括抖音直播间的实时观看人数等;
- 批处理:在抖音中,按天统计创造者的一些数据信息,比如 昨天的播放量有多少、评论量多少、广告收入多少; 工作流程:
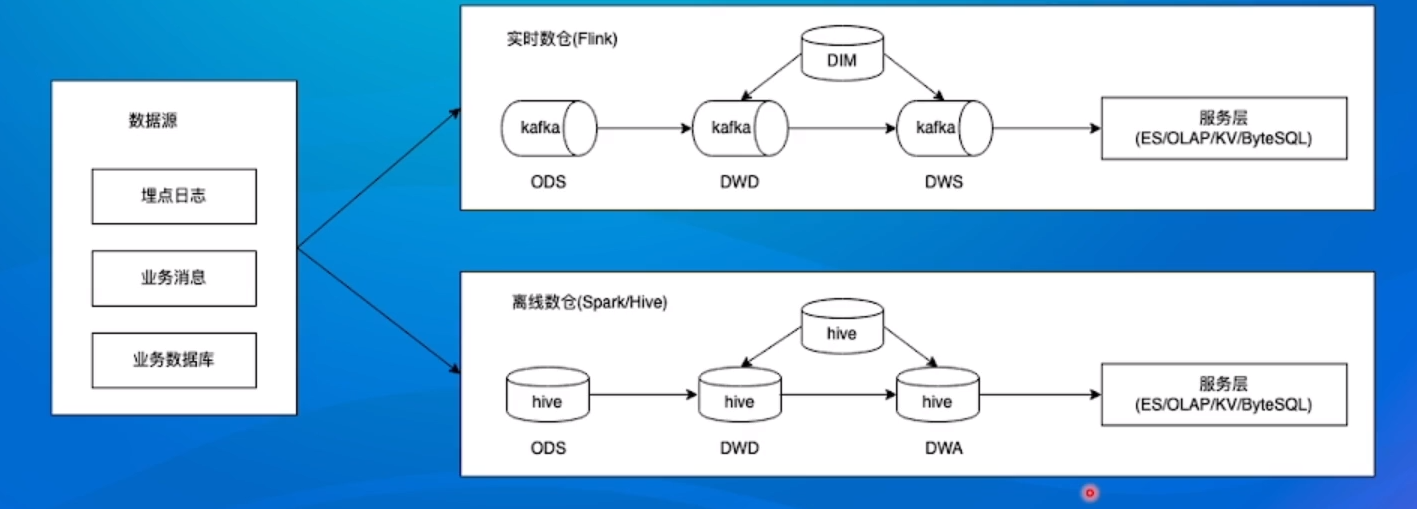 上述架构痛点:
上述架构痛点: - 人力成本比较高:批、流两套系统,相同逻辑需要开发两遍;
- 数据链路冗余:本身计算内容是一致的,由于是两套链路,相同逻辑需要运行两遍,产生一定的资源浪费;
- 数据口径不一致:两套系统、两套算子、两套UDF,通常会产生不同程度的误差,这些误差会给业务方带来非常大的困扰。
如何做到流批一体
- 批式计算是流式计算的特例,Everything is Streams,有界数据集(批式数据)也是一种数据流、一种特殊的数据流
- 从模块支持:
- SQL层;
- DataStream API层统一,批和流都可以使用DataStream API来开发.
- Scheduler层架构统一,支持流批场景;
- Failover Recovery层架构统一,支持流批场景
- Shuffle Service层架构统一,流批场景选择不同的Shuffle Service;
流批一体的Scheduler层
1.12 之前的 Flink 版本,Flink 支持两种调度模式:
| 模式 | 特点 | 场景 |
|---|---|---|
| EAGER | 申请一个作业所需要的全部资源,然后同时调度这个作业的全部 Task,所有的 Task 之间采取 Pipeline 的方式进行通信; | Streaming 场景 |
| LAZY | 先调度上游,等待上游产生数据或结束后再调度下游,类似 Spark 的 Stage 执行模式。 | Batch 场景 |
流批一体的Shuffle Service层
Shuffle:在分布式计算中,用来连接上下游数据交互的过程叫做Shuffle。实际上,分布式计算中所有涉及到上下游衔接的过程,都可以理解为 Shuffle;
针对不同的分布式计算框架,Shuffle通常有几种不同的实现:
- 基于文性的Pull Based Shuffle,比如Spark或MR,它的特点是具有较高的容错性,适合较大规模的批处理作业,由于是基于文件的,它的容错性和稳定性会更好一些;
- 基于Pipeline的Push Based Shuffle,比如Flink、Storm、.Presto等,它的特点是低延迟和高性能,但是因为shuffle数据没有存储下来,如果是batch任务的话,就需要进行重跑恢复;
流批Shuffle差异
| 流计算 | 批计算 | |
|---|---|---|
| 生命周期 | Shuffle数据与Task绑定 | Shuffle数据与Task是解耦的 |
| 数据存储介质 | 生命周期短,实时性要求,通常存储在内存 | 数据量大,有容错要求,存储在硬盘 |
| 部署方式 | 服务和计算节点部署在一起,减少网络开销(减少latency) | 分开部署(本机可能宕机,重跑代价大) |
流/批/OLAP业务场景概述
| 流式计算 | 批式计算 | 交互式分析 |
|---|---|---|
| 实时计算 | 离线计算 | OLAP |
| 延迟秒级以内 | 处理时间分钟到小时,甚至天级别 | 处理时间秒级 |
| 0~1s | 10s~1h+ | 1~10s |
| 广告推荐、金融风控 | 搜索引擎构建索引、批式数据分析 | 数据分析BI报表 |
| 三种业务场景的解决方案的要求及挑战是 | ||
| 模块 | 流式计算 | 批式计算 |
| -------- | ----------------------------------------------- | ------------------------- |
| SQL | Yes | Yes |
| 实时性 | 高,处理延迟毫秒级别 | 低 |
| 容错能力 | 高 | 中,大作业失败重跑代价高 |
| 状态 | Yes | No |
| 准确性 | Exactly Once,要求高,失败重跑需要恢复之前的状态 | Exactly Once,失败重跑即可 |
| 扩展性 | Yes | Yes |
Flink做OLAP的优势
- 引擎统一
- 降低学习成本
- 提高开发效率
- 提高维护效率
- 既有优势
- 内存计算
- Code-gen
- Pipeline Shuffle
- Session模式的MPP架构
- 生态支持
- 跨数据源查询支持
- TCP-DS基准测试性能强
Flink快速上手
第一个项目
- 新建maven项目 点击左上角"文件",点击"新建"后选择"项目"

- 配置pom.xml
<properties>
<flink.version>1.13.0</flink.version>
<java.version>1.13.0</java.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!--引入Flink相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>- 配置日志管理 在目录src/resource下添加文件
log4j.properties,内容配置如下:
log4i.rootLogger=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
Log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x -%m%n批处理
DataSet API方式实现批处理:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件读取数据
DataSource<String> lineDataSource = env.readTextFile("input/words.txt");
// 3。将每行数据进行分词,转换成二元组类型
FlatMapOperator<String, Tuple2<String, Long>> wordAndOneTuple = lineDataSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
// 将一行文本进行分词
String[] words = line.split(" ");
// 将每个单词转换成二元组输出
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
})
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 按照word进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOneTuple.groupBy(0);
// 5. 分组内进行聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneGroup.sum(1);
// 6. 打印结果
sum.print();
}
}有界流
DataStream方式实现WordCount:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Collection;
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
// 1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件
DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");
// 3. 转换计算
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
})
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
// 6. 打印输出
sum.print();
// 7. 启动执行
env.execute();
}
}输出格式如下: 
- 输出格式:执行并行子任务的编号(最小单位Task Slot) > (单词,出现次数)
- 输出特点
- 默认任务并行度为电脑CPU线程总数
- 多线程并行输出,所以不是顺序执行
- 相同字数由同一任务统计(子任务不知道别的任务统计到了多少次)
无界流
思路:数据源源不断,因此保持监听 操作步骤:
- 先执行
nc -lk 7777执行socket服务