Hadoop安装文档
2025年2月22日大约 17 分钟
1 Linux安装与基础操作
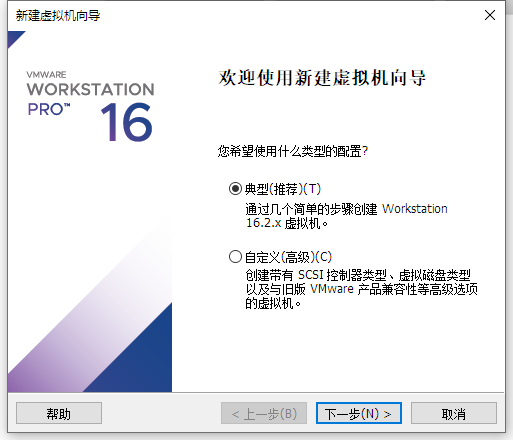
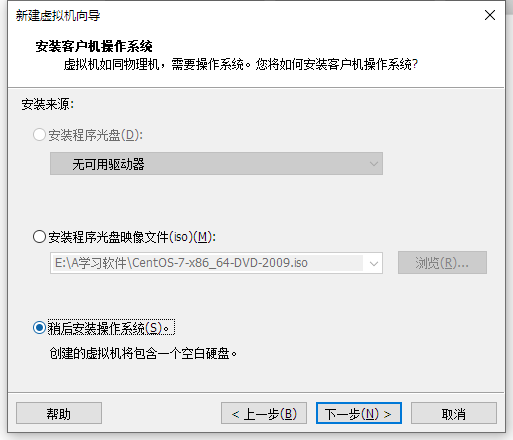
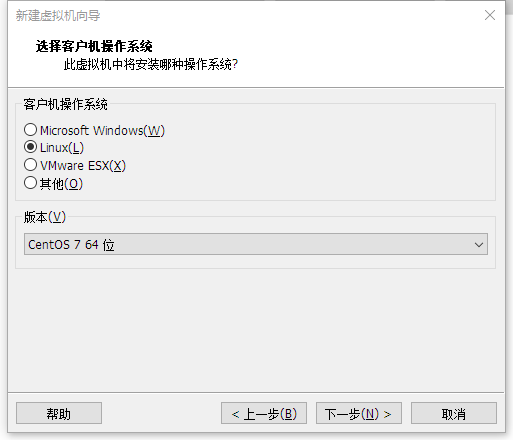
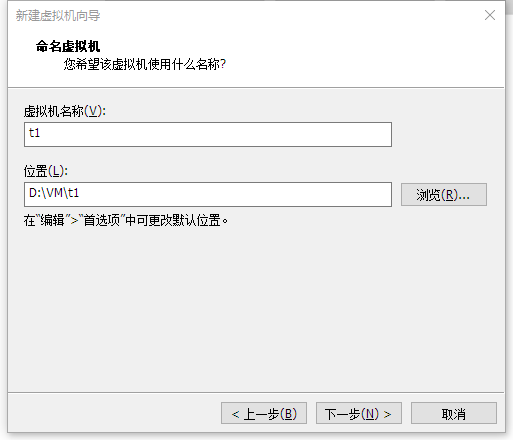
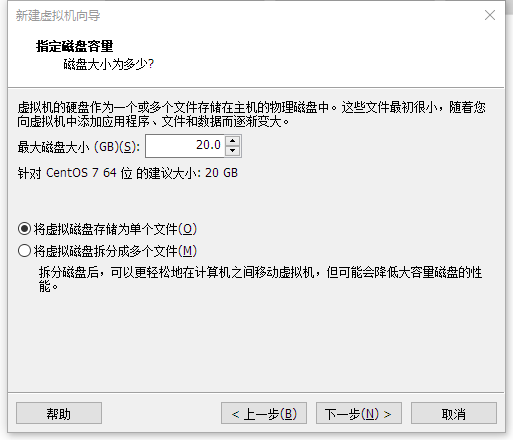
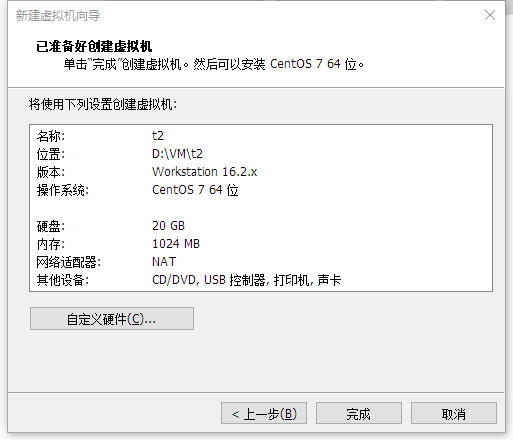
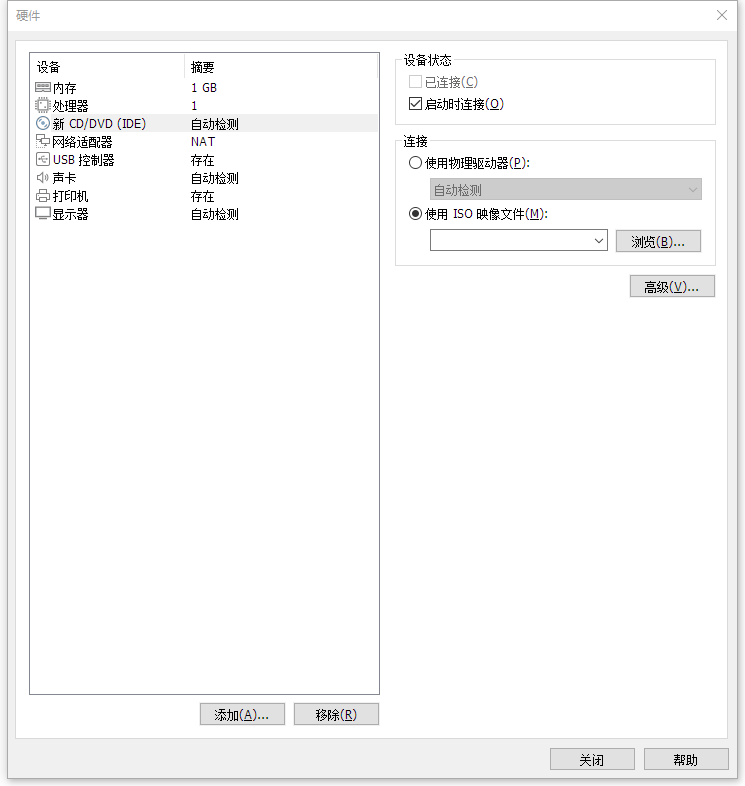
1.1 虚拟机安装系统
1.2系统内设置

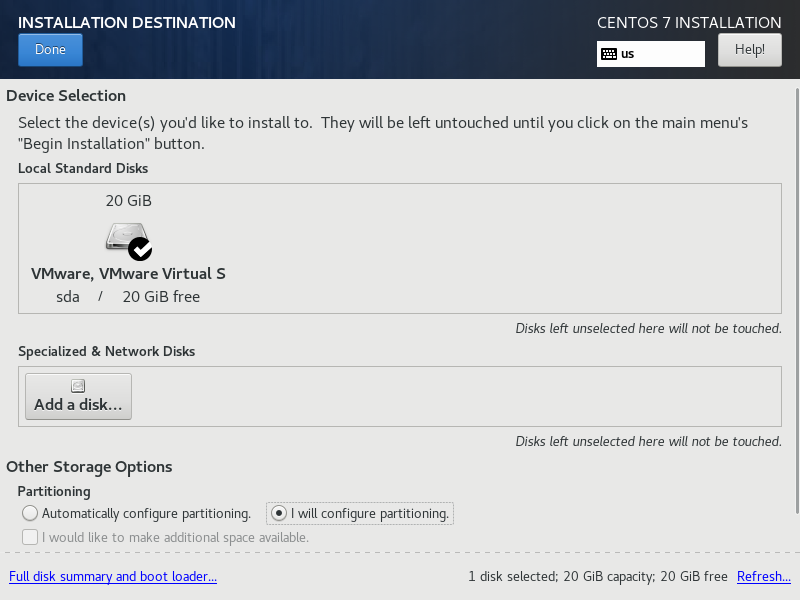
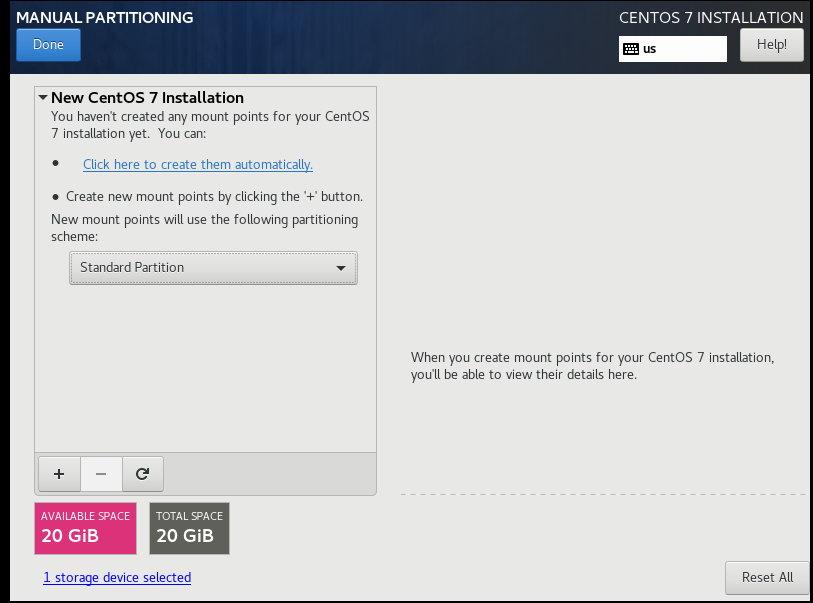
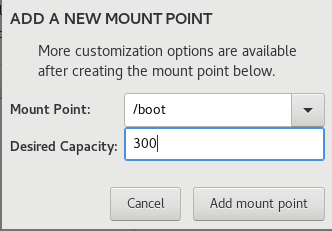
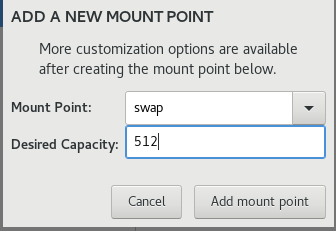
1.3Linux基本操作
改变目录
命令名称:cd
英文原意:change directory
执行权限:所有用户
功能描述:切换目录
语法:cd [目录]
特殊目录:
.:当前目录
..:上一级目录
cd ..回到上级目录
[root@hello1 ~]# cd /
[root@hello1 /]# ls
[root@hello1 /]# dir
[root@hello1 /]# ll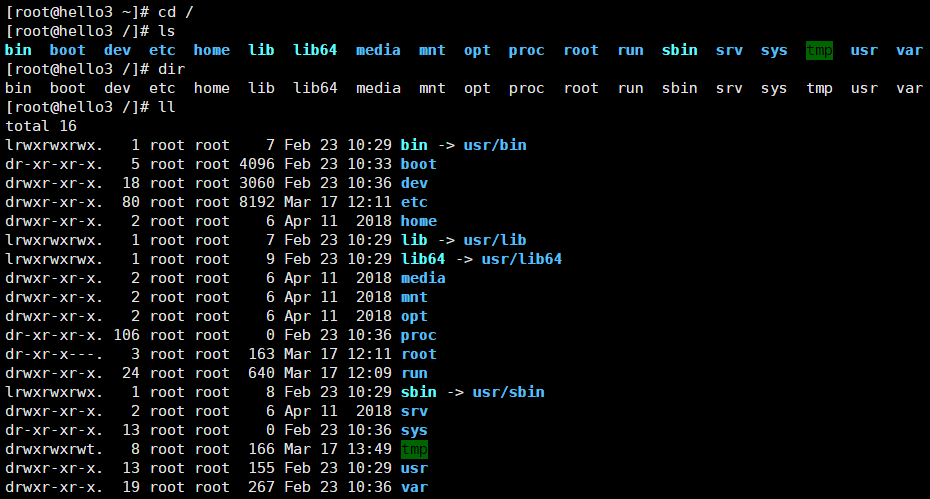
绝对路径
命令名称:pwd
英文原意:print working directory
执行权限:所有用户
功能描述:显示当前目录
语法:pwd
[root@hello1 /]# clear
[root@hello1 /]# cd /usr/local/had
[root@hello1 had]# pwd -d
-bash: pwd: -d: invalid option
pwd: usage: pwd [-LP]
[root@hello1 had]# pwd -P
/usr/local/had创建目录
命令名称:mkdir
英文原意:make directories
执行权限:所有用户
功能描述:创建新目录
[root@hello1 had]# mkdir dir1
[root@hello1 had]# mkdir /usr/local/had/dir1/dir11
[root@hello1 dir1]# mkdir /usr/local/had/dir1/dir11/dir112/dir1112
-p:递归创建
[root@hello1 dir11]# mkdir -p /usr/local/had/dir1/dir11/dir112/dir1112 递归创建
#善用tab键补全名称
[root@hello1 dir1112]# pwd -P
/usr/local/had/dir1/dir11/dir112/dir1112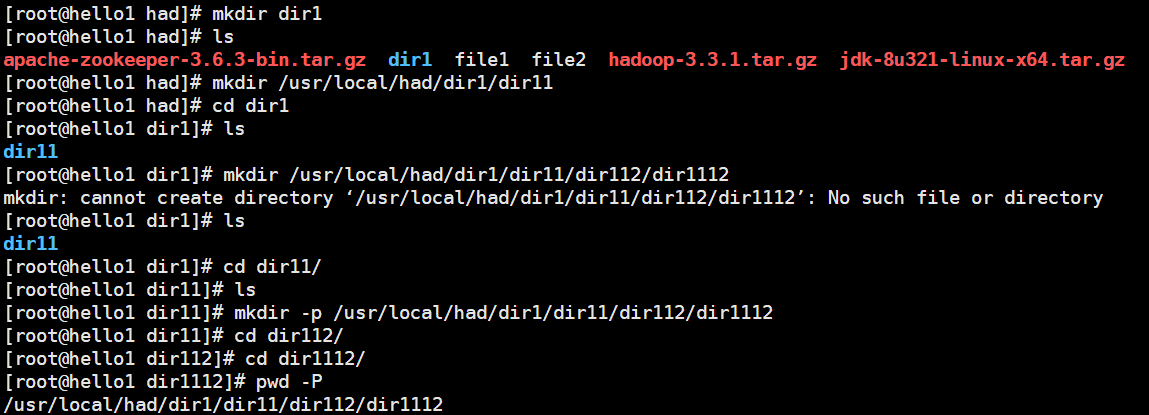
cp
命令名称:cp
英文原意:copy
执行权限:所有用户
功能描述:复制文件或目录
语法:cp -rp [源文件或目录] [目标目录]
-r:复制目录
-p:保留文件属性
rm
命令名称:rm
英文原意:remove
执行权限:所有用户
功能描述:删除文件
语法:rm -rf [文件或目录]
-r:删除目录
-f:强制删除
改名
[root@hello1 dir1]# ls
dir11 file1
[root@hello1 dir1]# cp file1 file3
[root@hello1 dir1]# cat file1
bigdata hadoop
[root@hello1 dir1]# cat file3
bigdata hadoop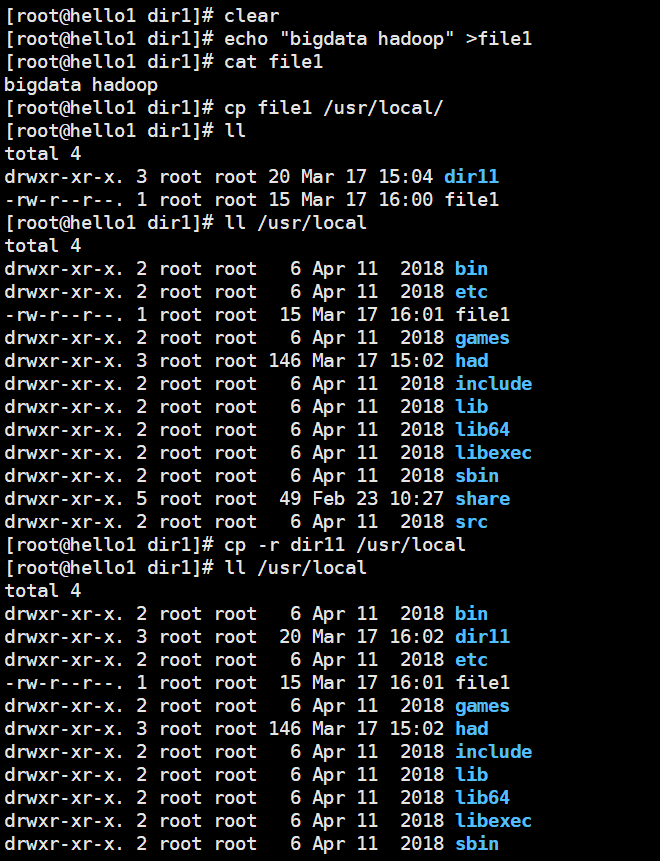
echo的重定向
(1)echo "content" > filename
将content覆盖到filename文件当中去,filename文件当中之前的内容不复存在了,实际上是修改了原文件的内容。
(2)echo "content" >> filename
将content追加到filename文件后,对filename文件之前的内容不修改,只进行增添,也叫追加重定向。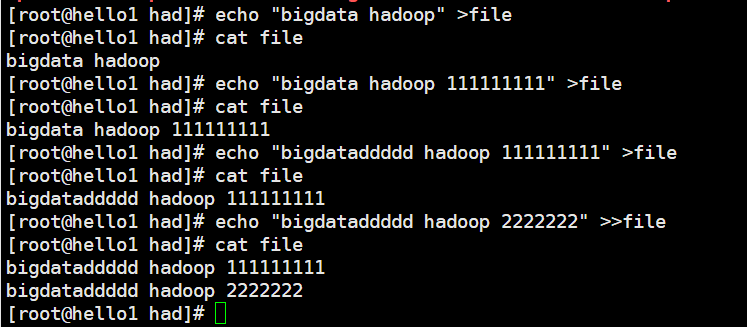
vim
vim编辑器有三种模式:
命令模式、编辑模式、末行模式
模式间切换方法:
(1)命令模式下,输入:后,进入末行模式
(2)末行模式下,按esc慢退、按两次esc快退、或者删除所有命令,可以回到命令模式
(3)命令模式下,按下i、a等键,可以计入编辑模式
(4)编辑模式下,按下esc,可以回到命令模式
rpm red-hat package manager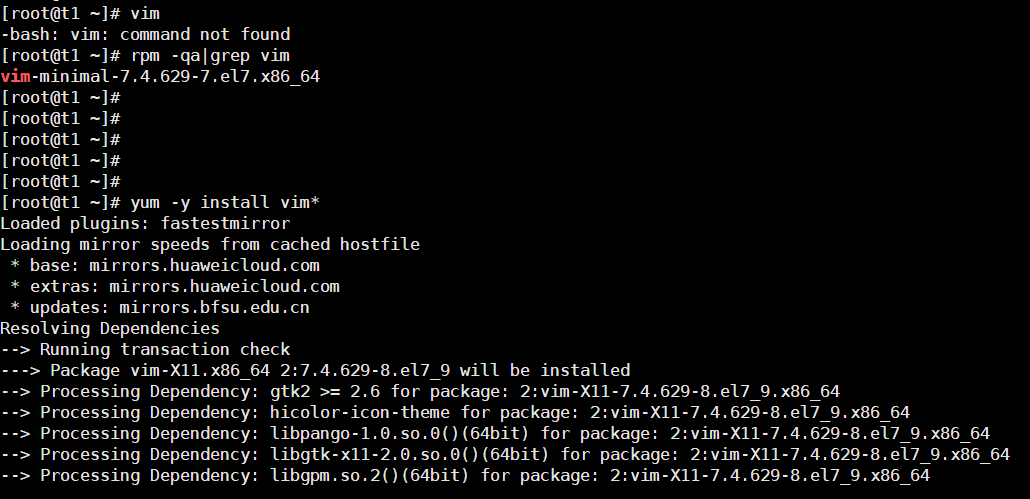
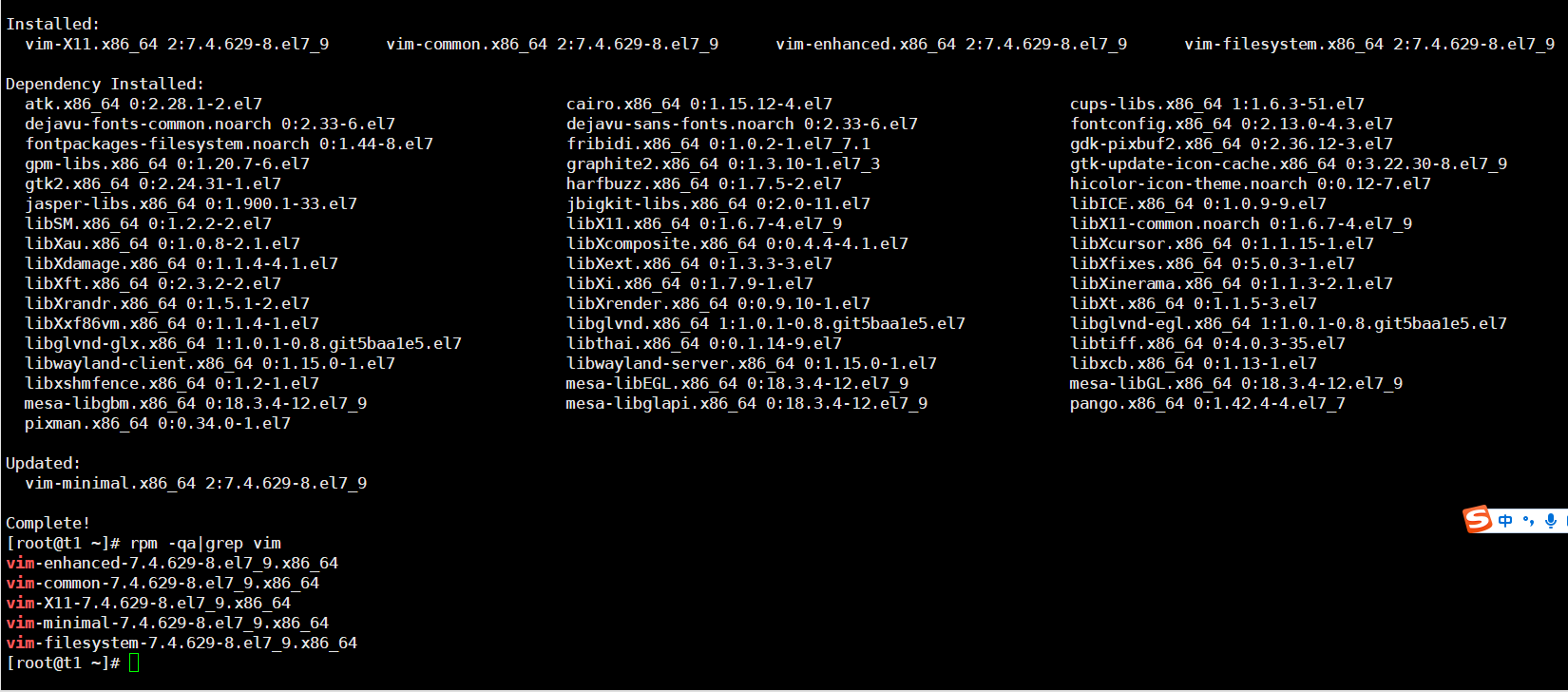
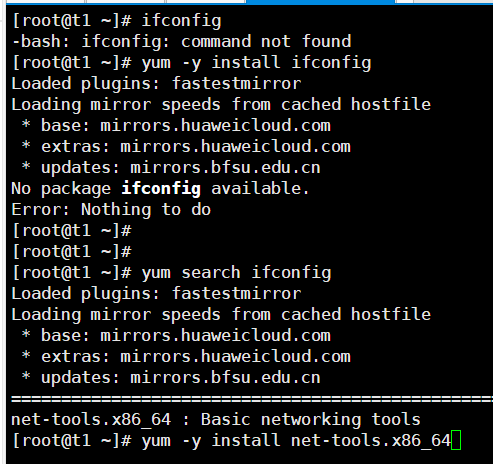
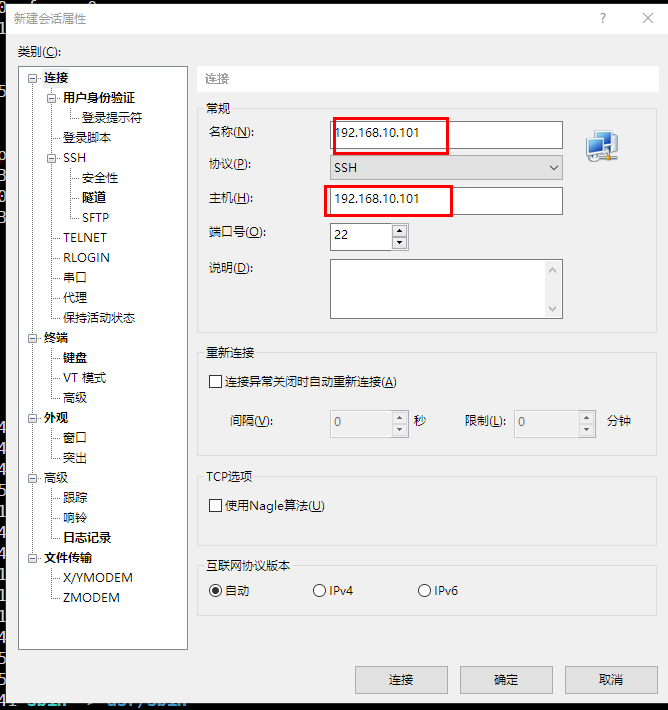
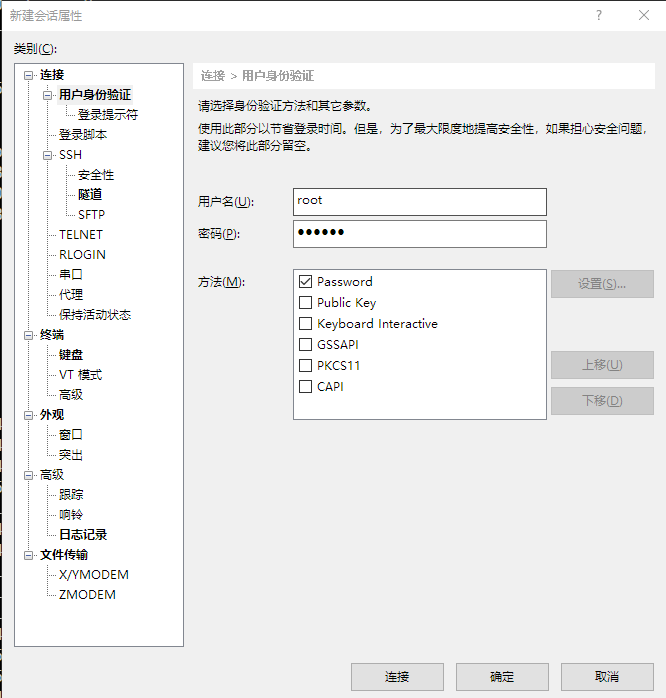
1.4Xshell远程连接
虚拟机设置
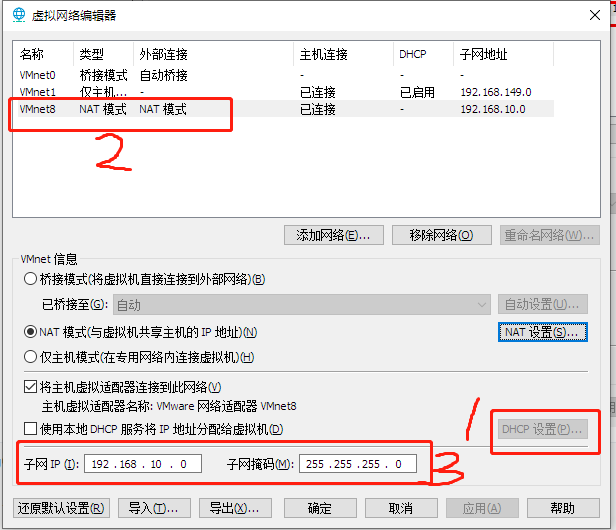
[root@hello ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens32
............
BOOTPROTO=static # 将dhcp改为static
............
ONBOOT=yes # 将no改为yes
IPADDR=192.168.10.101 # 添加IPADDR属性和ip地址
PREFIX=24 # 添加NETMASK=255.255.255.0或者PREFIX=24
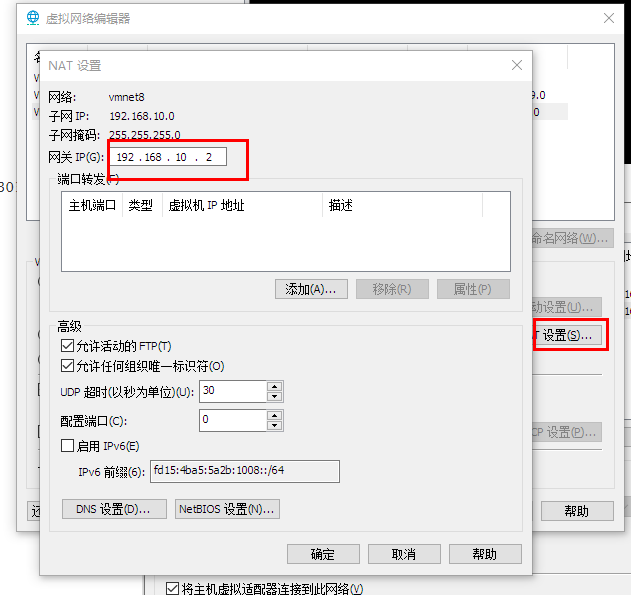
GATEWAY=192.168.10.2 # 添加网关GATEWAY
DNS1=114.114.114.114 # 添加DNS1和备份DNS
DNS2=8.8.8.8
--2. 重启网络服务
[root@hello1 ~]# systemctl restart network
或者
[root@hello1 ~]# service network restart
--3. 修改主机名(如果修改过,请略过这一步)
[root@localhost ~]# hostnamectl set-hostname hello1
或者
[root@localhost ~]# vi /etc/hostname
hello1
ping baidu.comXshell设置
1.5克隆主机
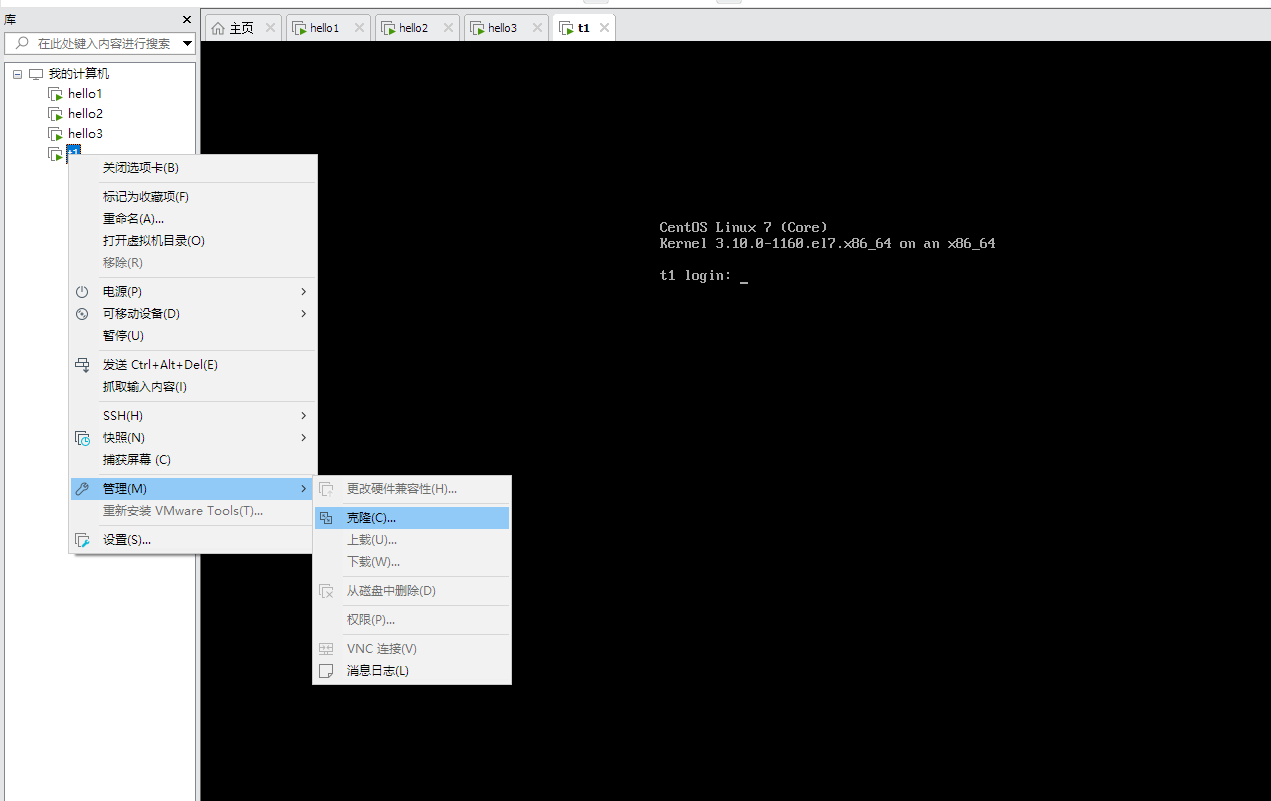
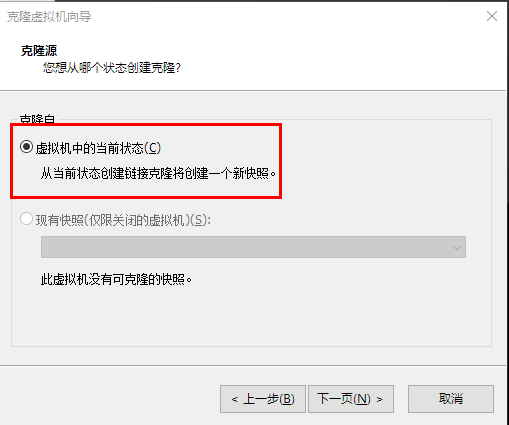
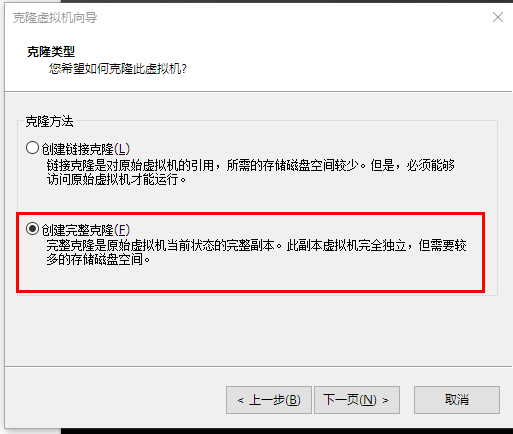
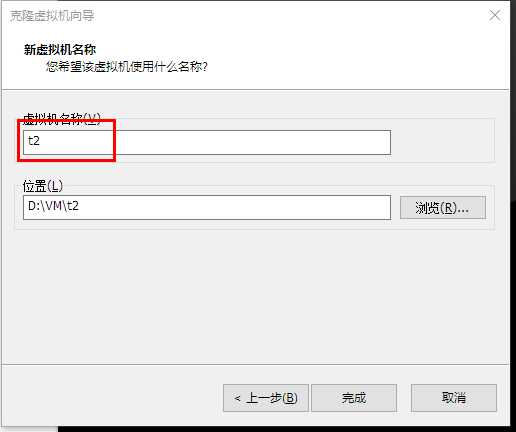
因为是克隆,所以主机名和IP都是一样的,需要调整
1.改变主机名
[root@hello ~]#vim /etc/hostname
t2
:wq
重启后生效
2.改变IP
[root@hello ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens32
............
IPADDR=192.168.10.101 # 调整剩余两台主机IP为 192.168.10.102和192.168.10.103
--2. 重启网络服务
[root@hello1 ~]# systemctl restart network
或者
[root@hello1 ~]# service network restart
[root@hello1 ~]# systemctl status network2 Hadoop集群设置
| 集群规划 | 规划 |
|---|---|
| 操作系统 | Mac、Windows |
| 虚拟软件 | Parallels Desktop(Mac)、VMWare(Windows) |
| 虚拟机 | 主机名: hello1, IP地址: 192.168.10.101 主机名: hello2, IP地址: 192.168.10.102 主机名: hello3, IP地址: 192.168.10.103 |
| 软件包上传路径 | /root/softwares |
| 软件包安装路径 | /usr/local |
| JDK | jdk-8u321-linux-x64.tar.gz |
| Hadoop | hadoop-3.3.1.tar.gz |
| 用户 | root |
2.1 完全分布式环境设置
1. 三台机器的防火墙必须是关闭的
2. 确保三台机器的网络配置通常(NAT模式、静态IP、主机名的配置)#之前在Xshell连接中已经设置
3. 确保/etc/hosts文件配置了IP和hosts的映射关系
4. 确保配置了三台机器的免密登录认证
5. 确保所有的机器时间同步
6. JDK和Hadoop的环境变量配置2.1.1 关闭防火墙
[root@hello1 ~]# systemctl stop firewalld
[root@hello1 ~]# systemctl disable firewalld
[root@hello1 ~]# systemctl stop NetworkManager
[root@hello1 ~]# systemctl disable NetworkManager
#最好也把selinux关闭掉,这是linux系统的一个安全机制,进入文件中将SELINUX设置为disabled
[root@hello1 ~]# vim /etc/selinux/config
.........
SELINUX=disabled
.........
#其他两台同样操作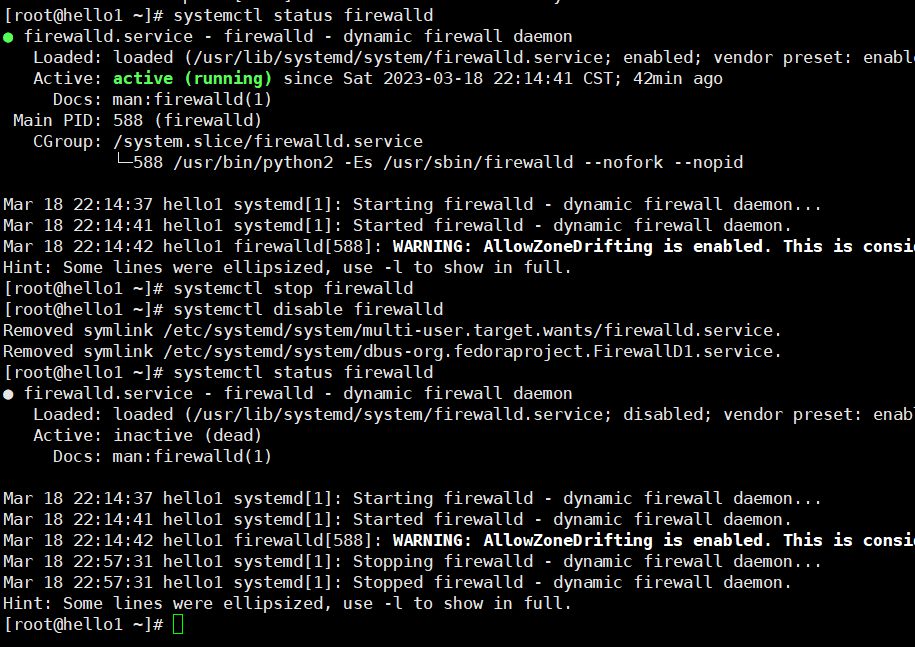
2.1.3免密登录
-1. 使用rsa加密技术,生成公钥和私钥。一路回车即可
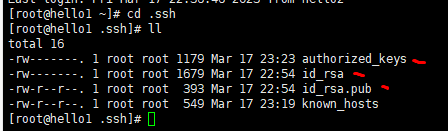
[root@hello1 ~]# cd ~
[root@hello1 ~]# ssh-keygen -t rsa
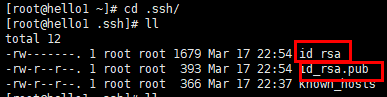
-2. 进入~/.ssh目录下,使用ssh-copy-id命令
[root@hello1 ~]# cd ~/.ssh
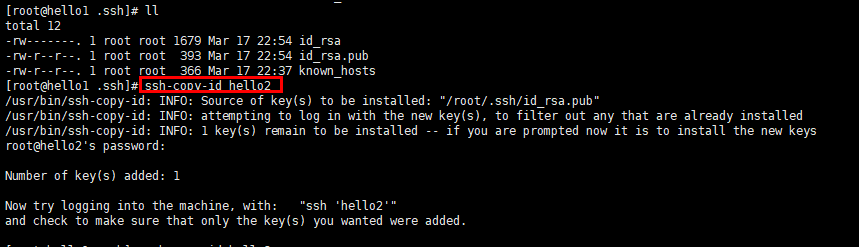
[root@hello1 .ssh]# ssh-copy-id root@hello1 hello2 hello3
-3. 进行验证
[hadoop@hello1 .ssh]# ssh hello1
#下面的第一次执行时输入yes后,不提示输入密码就对了
[hadoop@hello1 .ssh]# ssh localhost
[hadoop@hello1 .ssh]# ssh 0.0.0.0
注意:三台机器提前安装好的情况下,需要同步公钥文件。如果使用克隆技术。那么使用同一套密钥对就方便多了。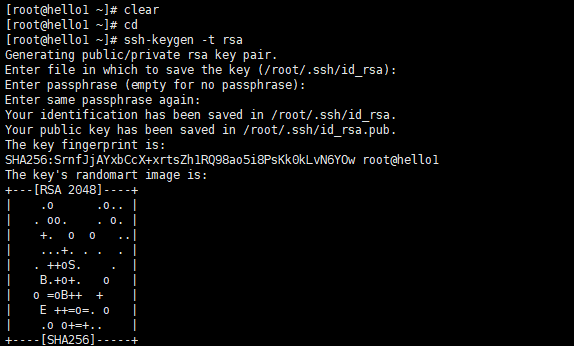
免密登录的工作原理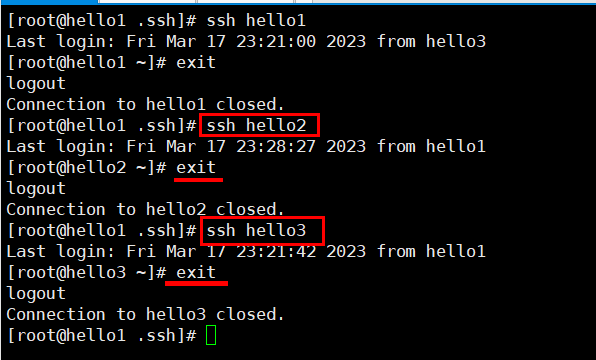
2.1.4 时间同步
# 选择集群中的某一台机器作为时间服务器,例如hello1 30s
# 保证这台服务器安装了ntp.x86_64。
[root@hello1 ~]# yum -y install ntp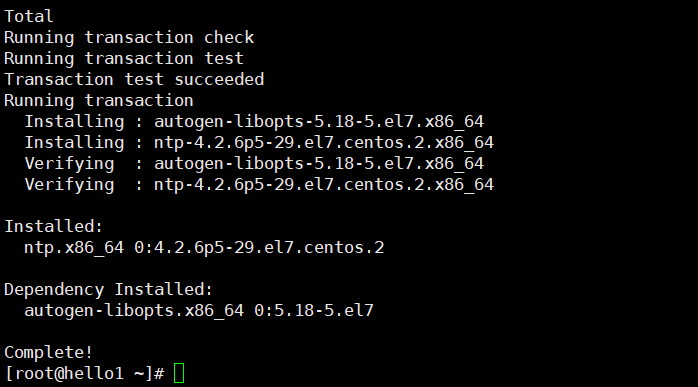
[root@hello1 ~]#system status ntp
ntpd.service - Network Time Service
Loaded: loaded (/usr/lib/systemd/system/ntpd.service; disabled; vendor preset: disabled)
Active: inactive (dead)
# 配置相应文件:
[root@hello1 ~]# vim /etc/ntp.conf
# Hosts on local network are less restricted.
# restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
# 添加集群中的网络段位
restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
# server 0.centos.pool.ntp.org iburst 注释掉
# server 1.centos.pool.ntp.org iburst 注释掉
# server 2.centos.pool.ntp.org iburst 注释掉
# server 3.centos.pool.ntp.org iburst 注释掉
server 127.127.1.0 -master作为服务器
:wq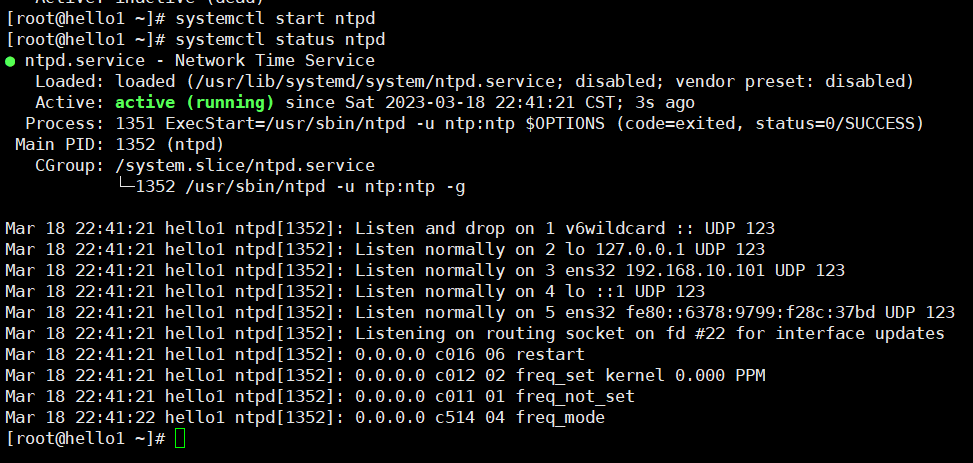
#开启服务
[root@hello1 ~]# systemctl start ntpd
[root@hello1 ~]# systemctl status ntpd
# 开机自启动:
[root@hello1 ~]# systemctl enable ntpd
# 其他服务器与hello1 时间同步
[root@hello2 ~]# yum -y install ntpdate
[root@hello3 ~]# yum -y install ntpdate
[root@hello2 ~]# ntpdate -u hello1
[root@hello3 ~]# ntpdate -u hello1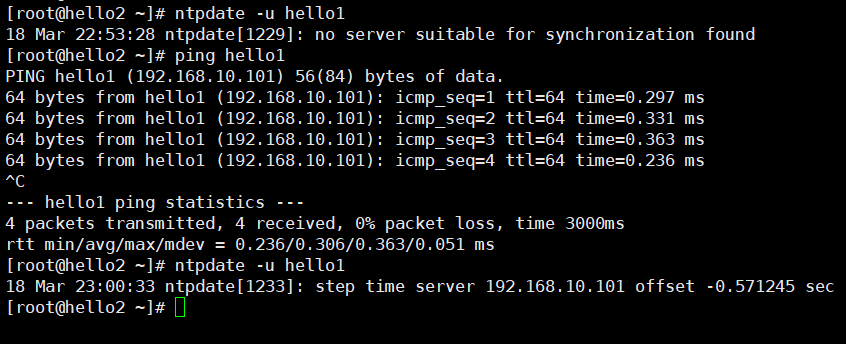
# 保证ntpd 服务运行......
[root@hello1 ~]# skudo service ntpd start
# 其他机器要保证安装ntpdate.x86_64
# 其他机器要使用root定义定时器
crontable -e
[root@hello2 ~]# crontab -e
*/1 * * * * /usr/sbin/ntpdate -u hello1
2.2 完全分布式环境-软件安装与配置
2.2.0 上传文件
文件上传至Linux
[root@hello1 softwares]# yum -iy install lrzsz
[root@hello1 softwares]# rpm -qa|grep lrzsz
lrzsz-0.12.20-36.el7.x86_64
[root@hello1 softwares]# rz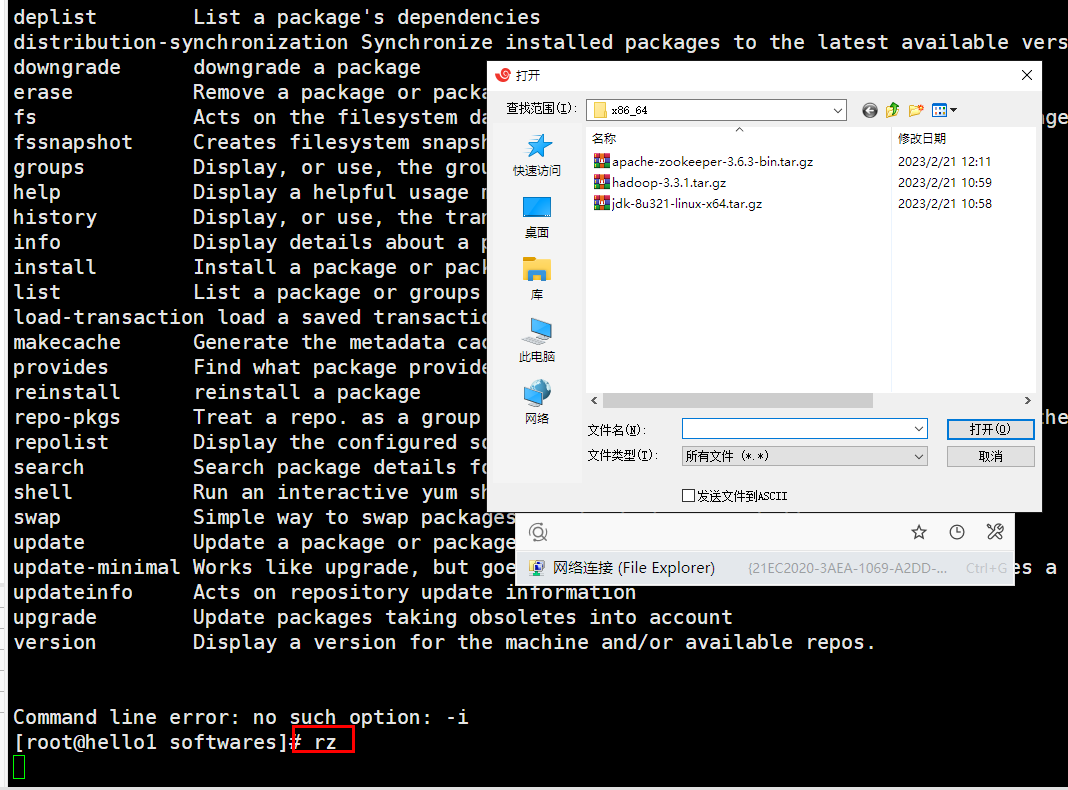
2.2.1 安装Java
[root@hello1 ~]# rpm -qa | grep jdk # 如果有,请卸载
[root@hello1 ~]# rpm -e xxxxxxxx --nodeps # 将查询到的内置jdk强制卸载
[root@hello1 softwares]# tar -zvxf jdk-8u321-linux-x64.tar.gz -C /usr/local/
[root@hello1 softwares]# cd /usr/local
改名
[root@hello1 local]# mv jdk1.8.0_321/ jdk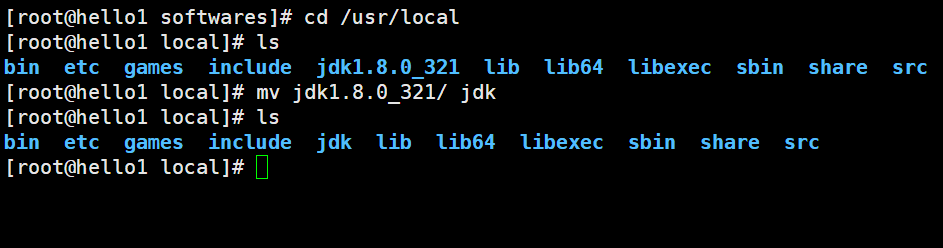
2.2.2 配置Java环境变量
[root@hello1 ~]# vim /etc/profile
.........省略...........
#jdk environment
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$PATH
:wq
[root@hello1 ~]# source /etc/profile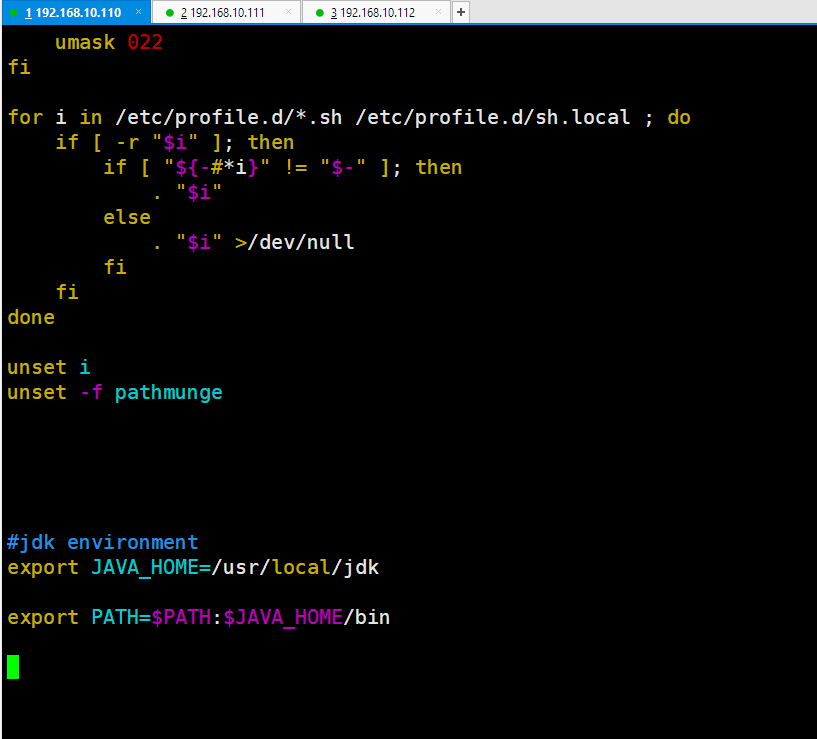
验证jdk是否生效
[root@hello1 ~]# java -version
java version "1.8.0_321"
Java(TM) SE Runtime Environment (build 1.8.0_321-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.321-b07, mixed mode)2.2.3安装Hadoop
[root@hello1 ~]# cd /usr/softwares/
[root@hello1 softwares]# tar -zxvf hadoop-3.3.1.tar.gz -C /usr/local/
[root@hello1 softwares]# cd /usr/local
改名
[root@hello1 local]# mv hadoop-3.3.1/ hadoop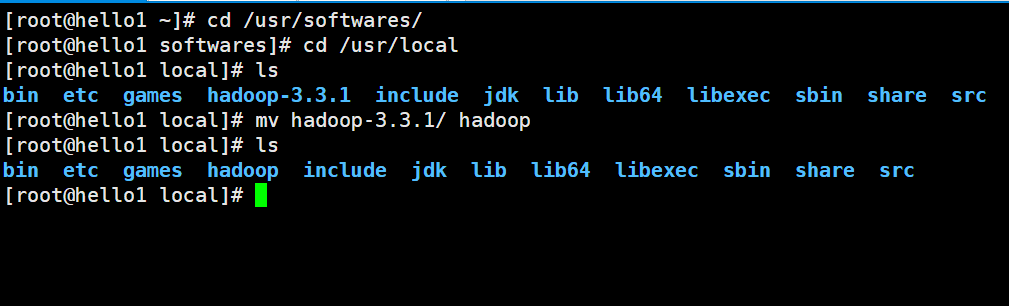
2.2.4 配置Hadoop环境变量
[root@hello1 ~]# vim /etc/profile
.........省略...........
#jdk environment
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$PATH
#hadoop environment
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
:wq
[root@hello1 ~]# source /etc/profile2.3 Hadoop的配置文件
我们需要通过配置若干配置文件,来实现Hadoop集群的配置信息。需要配置的文件有:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
在Hadoop安装完成后,会在$HADOOP_HOME/share路径下,有若干个*-default.xml文件,这些文件中记录了默认的配置信息。同时,在代码中,我们也可以设置Hadoop的配置信息。
这些位置配置的Hadoop,优先级为: 代码设置 > *-site.xml > *-default.xml 集群规划:
+--------------+---------------------+
| Node | Applications |
+--------------+---------------------+
| hello1 | NameNode |
| | DataNode |
| | ResourceManager |
| | NodeManagere |
+--------------+---------------------+
| hello2 | SecondaryNameNode |
| | DataNode |
| | NodeManager |
+--------------+---------------------+
| hello3 | DataNode |
| | NodeManager |
+--------------+---------------------+2.3.1 core-site.xml
[root@hello1 hadoop]# pwd
/usr/local/hadoop/etc/hadoop
[root@hello1 hadoop]# vim core-site.xml
<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<!-- 在Hadoop1.x的版本中,默认使用的端口是9000。在Hadoop2.x的版本中,默认使用端口是8020 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hello1:8020</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>2.3.2 hdfs-site.xml
[root@hello1 hadoop]# vim hdfs-site.xml
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hello2:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>hello1:9870</value>
</property>
</configuration>2.3.3 mapred-site.xml
[root@hello1 hadoop]# vim mapred-site.xml
<configuration>
<!-- 指定mapreduce使用yarn资源管理器-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 配置作业历史服务器的地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hello1:10020</value>
</property>
<!-- 配置作业历史服务器的http地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hello1:19888</value>
</property>:
</configuration>2.3.4 yarn-site.xml
[root@hello1 hadoop]# vi yarn-site.xml
<configuration>
<!-- 指定yarn的shuffle技术-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hello1</value>
</property>
<!--配置resourcemanager的web ui 的监控页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hello1:8088</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>2.3.5 hadoop-env.sh
[root@hello1 hadoop]# vi hadoop-env.sh
.........
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
.........2.3.6 workers
此文件用于指定datanode守护进程所在的机器节点主机名
[root@hello1 hadoop]# vim workers
hello1
hello2
hello32.3.7编写集群分发脚本xsync
rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
选项参数说明
选项 功能
-a 归档拷贝
-v 显示复制过程
(2)案例实操
(a)删除hello3中/opt/module/hadoop-3.1.3/wcinput
[root@hello3 hadoop-3.1.3]$ rm -rf wcinput/
(b)同步hello2中的/opt/module/hadoop-3.1.3到hello3
[root@hello2 module]$ rsync -av hadoop-3.1.3/ root@hello3:/opt/module/hadoop-3.1.3/
xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /opt/module root@hello3:/opt/
(b)期望脚本:
xsync要同步的文件名称
(c)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
[root@hello2 ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/root/.local/bin:/home/root/bin:/opt/module/jdk1.8.0_212/bin
(3)脚本实现
(a)在/home/root/bin目录下创建xsync文件
[root@hello2 opt]$ cd /home/root
[root@hello2 ~]$ mkdir bin
[root@hello2 ~]$ cd bin
[root@hello2 bin]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hello1 hello2 hello3
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done# 同步jdk Hadoop到另外两台节点
[root@hello1 ~]# cd /usr/local
[root@hello2 local]# scp -r jdk hello2:$PWD
[root@hello2 local]# scp -r jdk hello3:$PWD
[root@hello2 local]# scp -r hadoop hello2:$PWD
[root@hello2 local]# scp -r hadoop hello3:$PWD
# 同步profile到另外两台节点
[root@hello1 ~]# scp /etc/profile hello2:/etc
[root@hello1 ~]# scp /etc/profile hello3:/etc
#生效
[root@hello2 ~]# source /etc/profile
[root@hello3 ~]# source /etc/profile
# 检查workers节点上的jdk是否已安装
# 检查是否同步了/etc/hosts文件3 格式化与启动
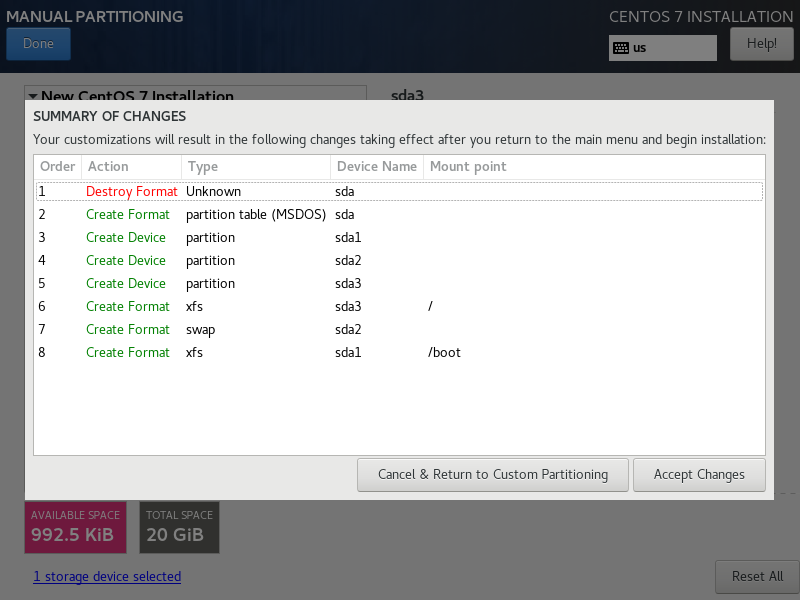
3.1 格式化集群
**1)**在注意:
(1)如果集群是第一次启动,需要在hello2节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)hello1机器上运行命令
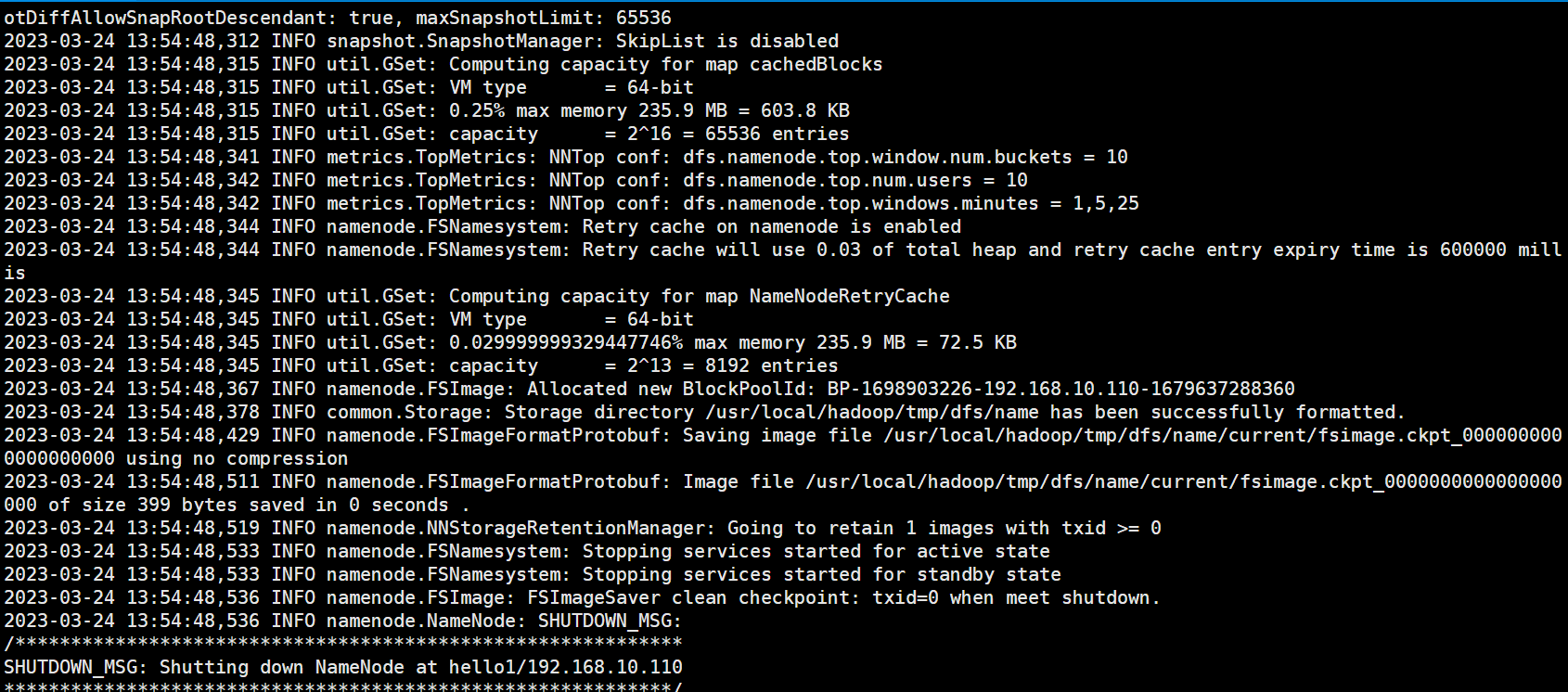
[root@hello1 ~]# hdfs namenode -format**2)**格式化的相关信息解读
--1. 生成一个集群唯一标识符:clusterid
--2. 生成一个块池唯一标识符:blockPoolId
--3. 生成namenode进程管理内容(fsimage)的存储路径:
默认配置文件属性hadoop.tmp.dir指定的路径下生成dfs/name目录
--4. 生成镜像文件fsimage,记录分布式文件系统根路径的元数据
--5. 其他信息都可以查看一下,比如块的副本数,集群的fsOwner等。参考图片
3) 目录里的内容查看
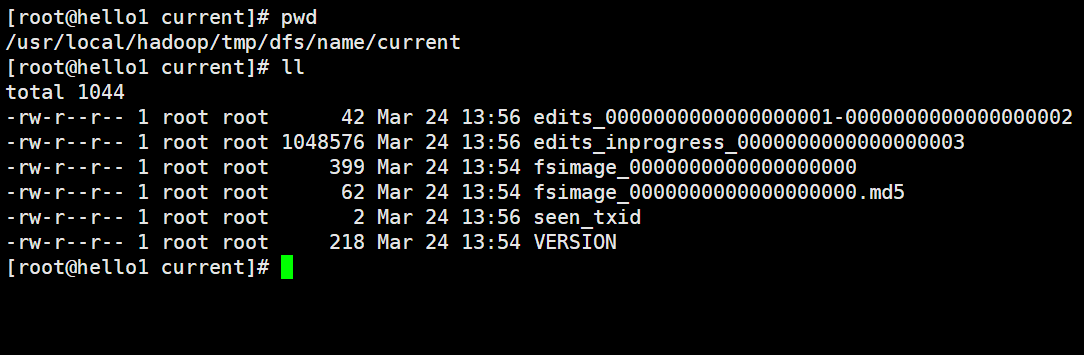
3.2启动集群
1) 启动脚本和关闭脚本介绍
1. 启动脚本
-- start-dfs.sh :用于启动hdfs集群的脚本
-- start-yarn.sh :用于启动yarn守护进程
-- start-all.sh :用于启动hdfs和yarn
2. 关闭脚本
-- stop-dfs.sh :用于关闭hdfs集群的脚本
-- stop-yarn.sh :用于关闭yarn守护进程
-- stop-all.sh :用于关闭hdfs和yarn
3. 单个守护进程脚本
# hdfs --daemon start 单独启动⼀个进程
hdfs --daemon start namenode # 只开启NameNode
hdfs --daemon start datanode # 只开启DataNode
hdfs --daemon start secondarynamenode # 只开启SecondaryNameNode
# hdfs --daemon stop 单独停⽌⼀个进程
hdfs --daemon stop namenode # 只停⽌NameNode
hdfs --daemon stop datanode # 只停⽌DataNode
hdfs --daemon stop secondarynamenode # 只停⽌SecondaryNameNode
# hdfs --workers --daemon start 启动所有的指定进程
hdfs --workers --daemon start namenode
hdfs --workers --daemon start datanode # 开启所有节点上的DataNode
hdfs --workers --daemon start secondarynamenode
# hdfs --workers --daemon stop 停止所有的指定进程
hdfs --workers --daemon stop namenode
hdfs --workers --daemon stop datanode # 停⽌所有节点上的DataNode
hdfs --workers --daemon stop secondarynamenode- jps查看进程
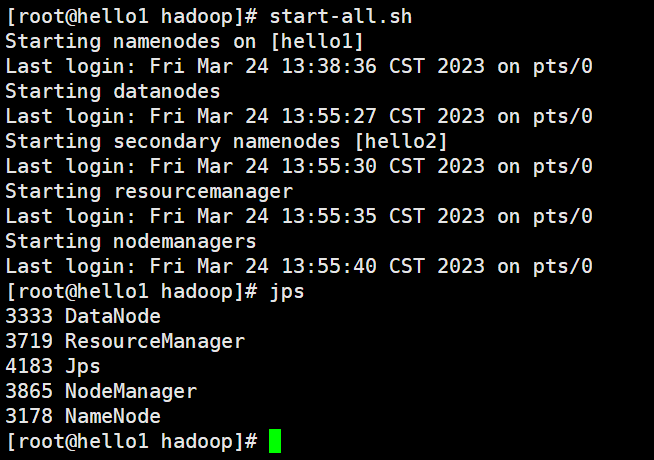
--1. 在hello1上运行jps指令,会有如下进程
5712 ResourceManager
7441 DataNode
5858 NodeManager
5175 NameNode
7960 Jps
--2. 在hello2上运行jps指令,会有如下进程
3890 DataNode
4052 Jps
3500 SecondaryNameNode
3582 NodeManager
--3. 在hello3上运行jps指令,会有如下进程
3235 NodeManager
3516 DataNode
3628 Jps4)webui查看
Web端查看HDFS的NameNode
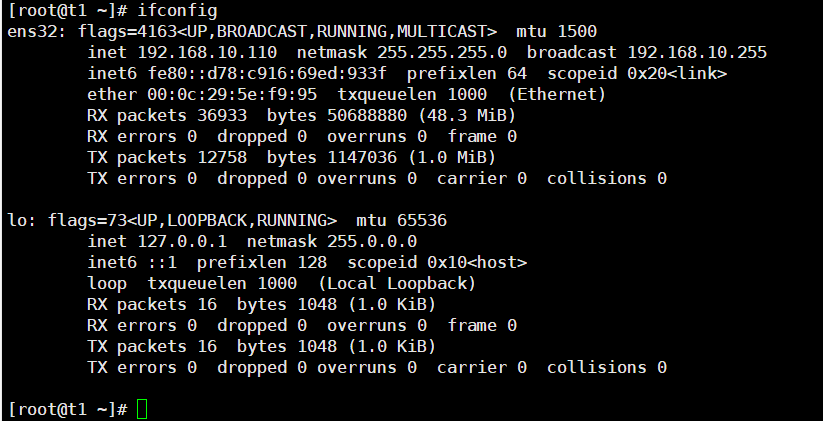
HDFS: http://192.168.10.110:9870
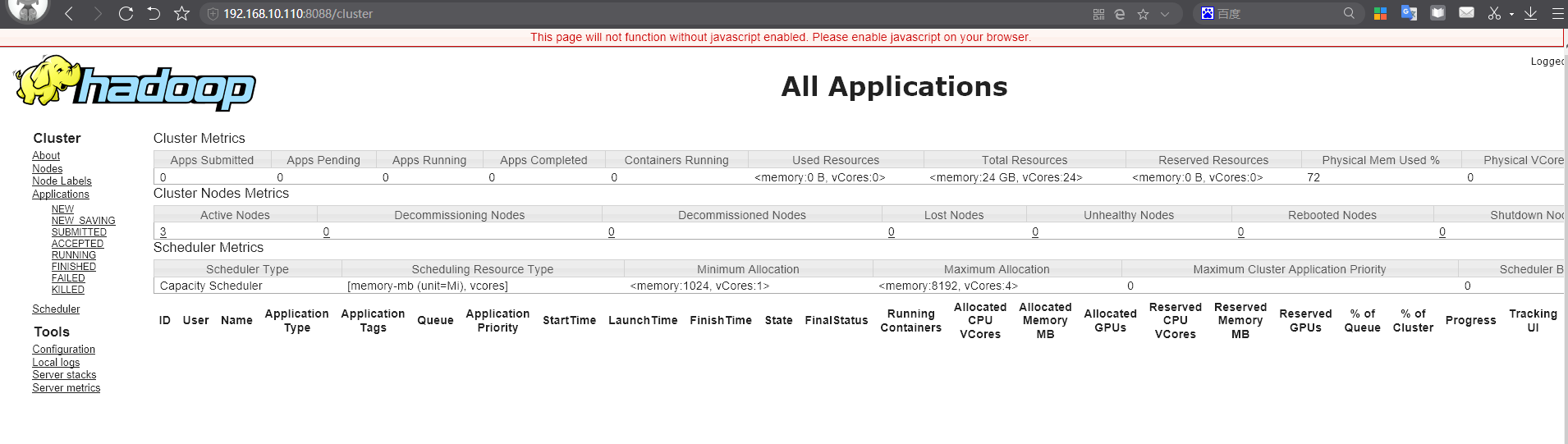
Web端查看YARN的ResourceManager
YARN: http://192.168.10.110:8088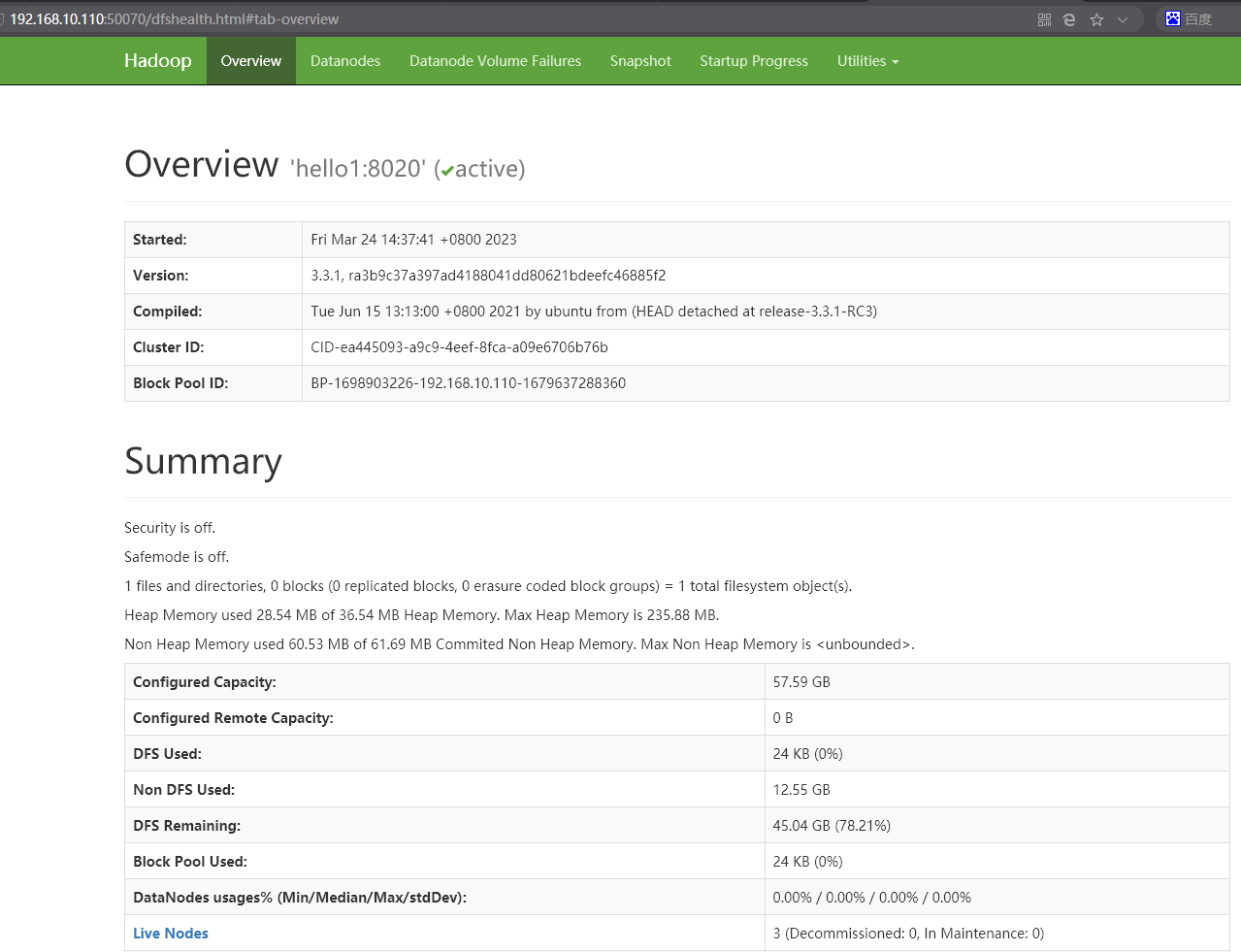
4 HDFS的Shell命令
HDFS其实就是一个分布式的文件系统,我们可以使用一些命令来操作这个分布式文件系统上的文件。
- 访问HDFS的命令:
hadoop fs
hdfs dfs
- 小技巧
1. 在命令行中输入hdfs,回车后,就会提示hdfs后可以使用哪些命令,其中有一个是dfs。
2. 在命令行中输入hdfs dfs,回车后,就会提示dfs后可以添加的一些常用shell命令。
- 注意事项
分布式文件系统的路径在命令行中,要从/开始写,即绝对路径。| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
2)-help:输出这个命令参数
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -help rm
3)创建/sanguo文件夹
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /sanguo4.1 上传
1)-moveFromLocal:从本地剪切粘贴到HDFS
[root@hadoop102 hadoop-3.1.3]$ vim shuguo.txt
输入:
shuguo
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo2)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[root@hadoop102 hadoop-3.1.3]$ vim weiguo.txt
输入:
weiguo
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo3)-put:等同于copyFromLocal,生产环境更习惯用put
[root@hadoop102 hadoop-3.1.3]$ vim wuguo.txt
输入:
wuguo
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo4)-appendToFile:追加一个文件到已经存在的文件末尾
[root@hadoop102 hadoop-3.1.3]$ vim liubei.txt
输入:
liubei
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt4.2 下载
1)-copyToLocal:从HDFS拷贝到本地
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
2)-get:等同于copyToLocal,生产环境更习惯用get
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt4.3 HDFS直接操作
1)-ls: 显示目录信息
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo
2)-cat:显示文件内容
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt
3)-chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -chown root:root /sanguo/shuguo.txt
4)-mkdir:创建路径
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
5)-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
6)-mv:在HDFS目录中移动文件
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo
7)-tail:显示一个文件的末尾1kb的数据
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
8)-rm:删除文件或文件夹
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:递归删除目录及目录里面内容
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
10)-du统计文件夹的大小信息
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx
说明:27表示文件大小;81表示27*3个副本;/jinguo表示查看的目录
11)-setrep:设置HDFS中文件的副本数量
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。