2025/2/22大约 3 分钟
刷机准备
- 必需
- MIUI底包-- V13.0.9.0.SKHEUXM(可以理解为底层驱动更新,为了适应新版本所需,如果放的链接下载不了,直接到gitub寻找所需版本)
- 刷机包(cDroid)(这里展示的是安卓13,需要别的版本另行下载)
- 可选
- Gapp(谷歌全家桶,按需下载,上面的页面里有小标签,点开可以下载)
- Magisk(Root与否,见仁见智)
- 左边Gapp,右边固件包

2025/2/22小于 1 分钟
数据流和动态表
传统SQL和流处理
| 特征 | SQL | 流处理 |
|---|---|---|
| 处理数据的有界性 | 处理的表是有界的 | 流是一个无限元祖序列 |
| 处理数据的完整性 | 执行查询可以访问完整的数据 | 执行查询无法访问所有的数据 |
| 执行时间 | 批处理查询产生固定大小结果后终止 | 查询不断更新结果,永不终止 |
2025/2/22大约 4 分钟
Flink简介
基本概念
Apache Flink是一个开源的流处理框架,应用于分布式、高性能、高可用的数据流应用程序。可以处理有限数据流和无限数据,即能够处理有边界和无边界的数据流。无边界的数据流就是真正意义上的流数据,所以Flink是支持流计算的。有边界的数据流就是批数据,所以也支持批处理的。不过Flink在流处理上的应用比在批处理上的应用更加广泛,统一批处理和流处理也是Flink目标之一。Flink可以部署在各种集群环境,可以对各种大小规模的数据进行快速计算。
2025/2/22大约 10 分钟
项目介绍
GRNet: 用于稠密点云补全的网格化残差网络
由于传感器本身的分辨率限制或物体的遮挡,现实场景中采集的点云往往不完整,而完整的点云对于点云理解有很大帮助。因此,点云补全在现实应用中有着非常重要的意义。
早期的工作(如3D-EPN [1])将该问题转换为体素的补全问题,然而转换为体素时会引入量化误差,从而丢失物体的细节。近几年的方法(如PCN[2]、TopNet [3]和Cascade Point Completion [4]等)直接使用多层感知机回归点云的坐标值。但由于点云的无序性,多层感知机无法很好地获得点云的几何结构和相邻点的上下文信息。
反观近几年点云分割的方法(如SPLATNet [5]和InterpConv [6]),它们在Permutohedral Lattice和3D Grid中进行卷积操作,从而考虑点云的空间结构和上下文信息。然而这两个方法假定点云中点的坐标和数量在输入输出时保持不变,因此无法直接用于点云补全。
为了解决上述问题,本文提出了**Gridding Residual Network(GRNet)**将无序的点云规则化至3D Grid,从而在点云补全中考虑了点云的空间结构和上下文信息,最终在点云补全任务中取得了更好的效果。
2025/2/22大约 6 分钟
Hadoop基本介绍
- Hadoop技术体系
- 存储层:HDFS
- 调度层:YARN
- 计算框架:MapReduce。值得注意的是另外一个同属于Apache基金会的开源计算框架Apache Spark,当前业界的使用已经远超于MapReduce,尽管它不属于Hadoop项目,但是和Hadoop也有紧密关系。
- 文件系统
- 单机文件系统:常见的如Windows NTFS,Linux的Ext4,虽然不同的操作系统和实现,但是本质都是一样的,解决相同的问题。
- 分布式文件系统
- 分布式文件系统是单机文件的延伸,概念术语是相通的,比如目录、文件、目录树等。
- 本质上扩展、延伸了单机文件系统,提供了大容量、高可靠、低成本等功能特性;实现上一般也更为复杂。
- 分布式存储系统,了解分布式存储系统的分类,理解不同存储系统的使用场景。直观的区别是用户使用方式,本质是针对不同的使用场景提供高效合理的系统。
- 对象存储:例如AWS的S3,阿里云的OSS,开源的Minio。
- 块存储:例如AWS的EBS,开源社区也有Ceph等。
- 文件系统:HDFS、GlusterFS、CubeFS等
- 数据库:KV数据库比如Cassandra,关系型数据库如TiDB、OceanBase等
- HDFS功能特性:需要注意HDFS尽管是一个文件系统,但是它没有完整实现POSIX文件系统规范。
2025/2/22大约 3 分钟
Environment Pytorch 1.0.1 Python 3.7.4
conda create -n FPNET python=3.7
conda activate FPNet2025/2/22小于 1 分钟
概述
OLAP
OLAP (OnLine Analytical Processing) 对业务数据执行多维分析,并提供复杂计算,趋势分析和复杂数据建模的能力。是许多商务智能(BI)应用程序背后的技术。现如今OLAP已经发展为基于数据库通过SQL对外提供分析能力
常见的OLAP引擎
- 预计算引擎:Kylin,Druid
- 批式处理引擎:Hie,Spark
- 流式处理引擎:Flink
- 交互式处理引擎:Presto,Clickhouse,Doris
2025/2/22大约 4 分钟
大数据体系
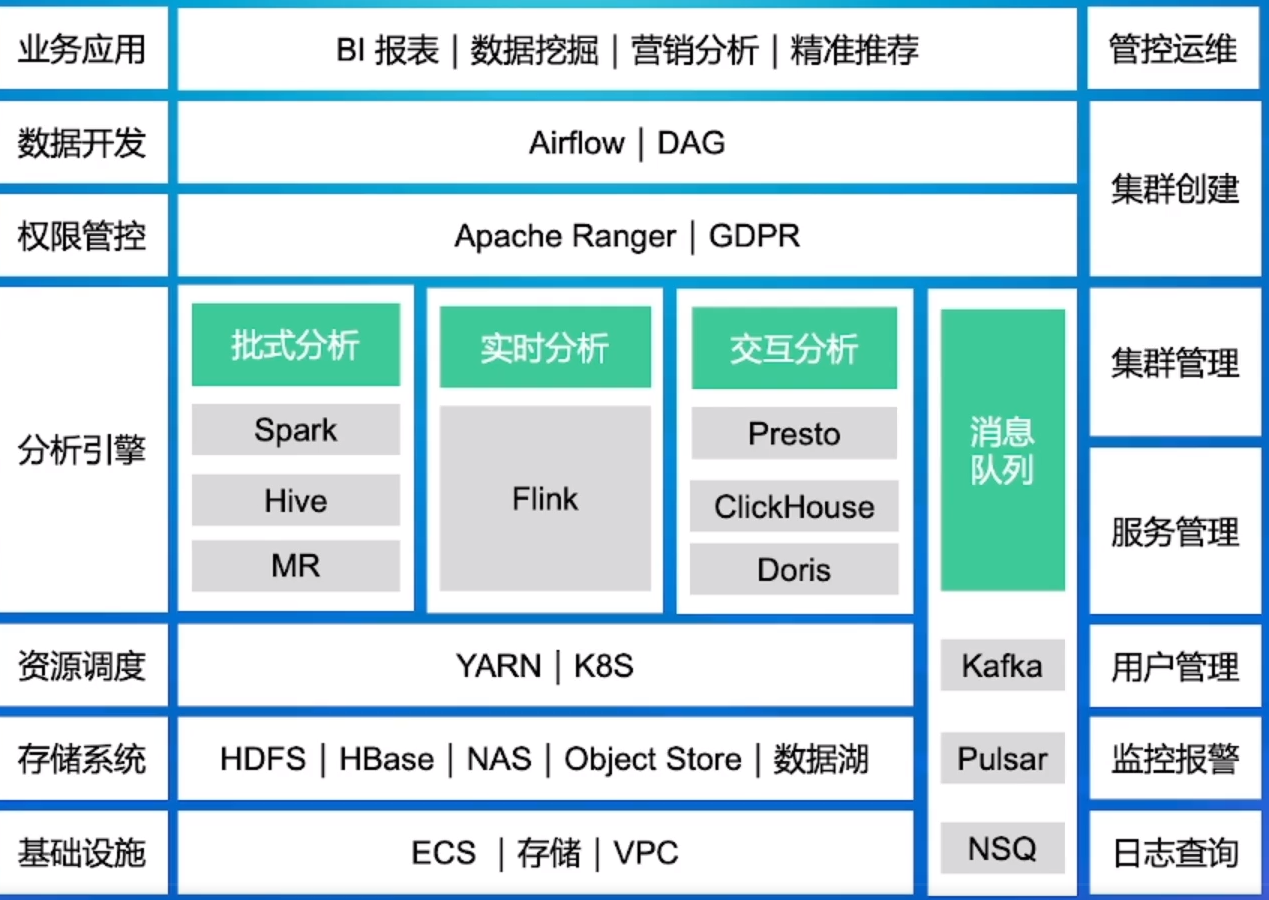
SQL查询优化器重要性
SQL重要性
- 有 MySQL、Oracle 之类使用 SQL 作为交互语言的数据库
- 有 JDBC、ODBC 之类和各种数据库交互的标准接口
- 有大量数据科学家和数据分析师等不太会编程语言但又要使用数据的人
- 多个大数据计算引擎都支持 SQL 作为更高抽象层次的计算入口
- MapReduce -> Hive SQL
- Spark -> Spark SQL
- [[Flink]] -> Flink SQL
2025/2/22大约 10 分钟
Spark介绍
大数据处理技术栈

开源大数据处理引擎
2025/2/22大约 1 分钟