数据流和动态表
传统SQL和流处理
| 特征 | SQL | 流处理 |
|---|---|---|
| 处理数据的有界性 | 处理的表是有界的 | 流是一个无限元祖序列 |
| 处理数据的完整性 | 执行查询可以访问完整的数据 | 执行查询无法访问所有的数据 |
| 执行时间 | 批处理查询产生固定大小结果后终止 | 查询不断更新结果,永不终止 |
2025/2/22大约 4 分钟
| 特征 | SQL | 流处理 |
|---|---|---|
| 处理数据的有界性 | 处理的表是有界的 | 流是一个无限元祖序列 |
| 处理数据的完整性 | 执行查询可以访问完整的数据 | 执行查询无法访问所有的数据 |
| 执行时间 | 批处理查询产生固定大小结果后终止 | 查询不断更新结果,永不终止 |
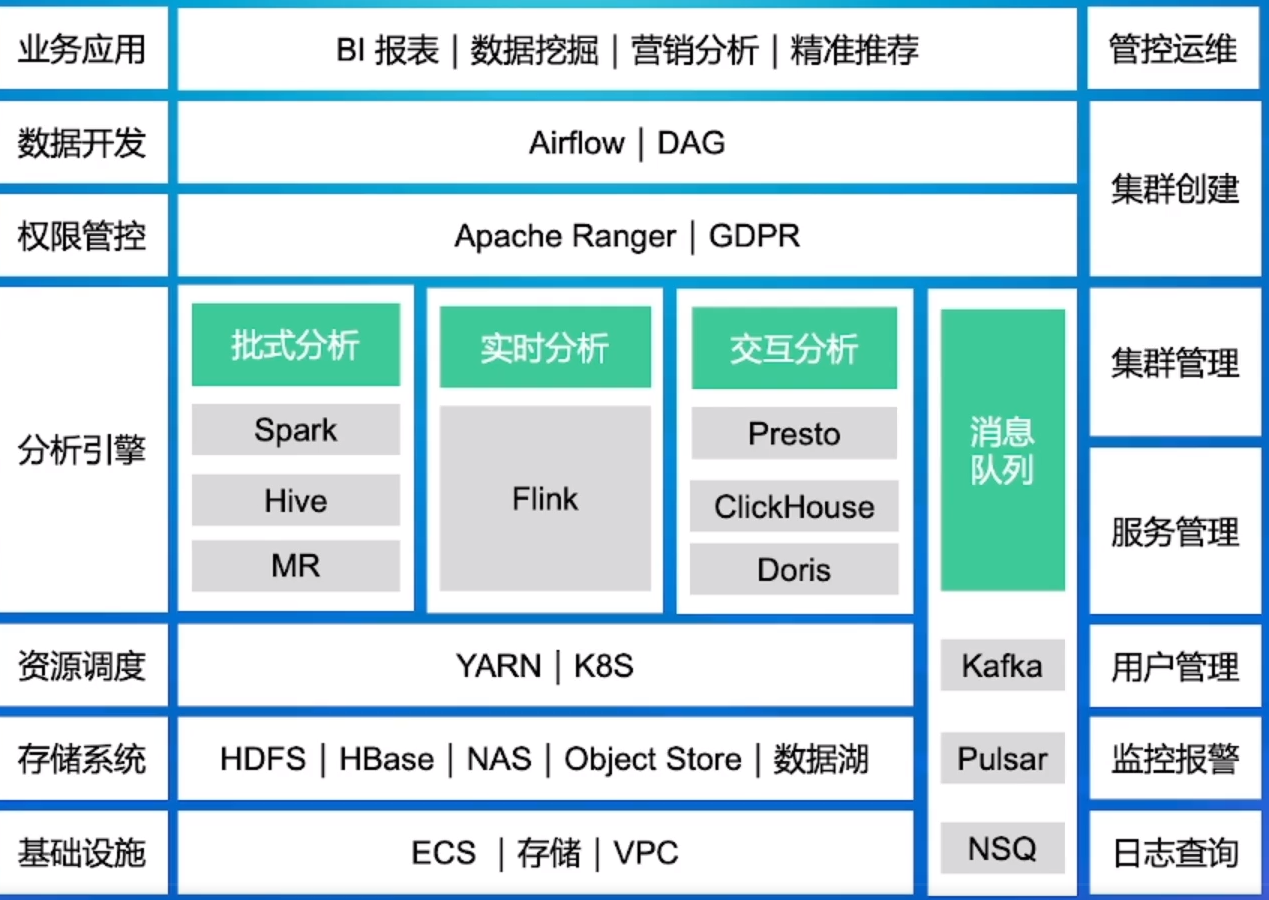
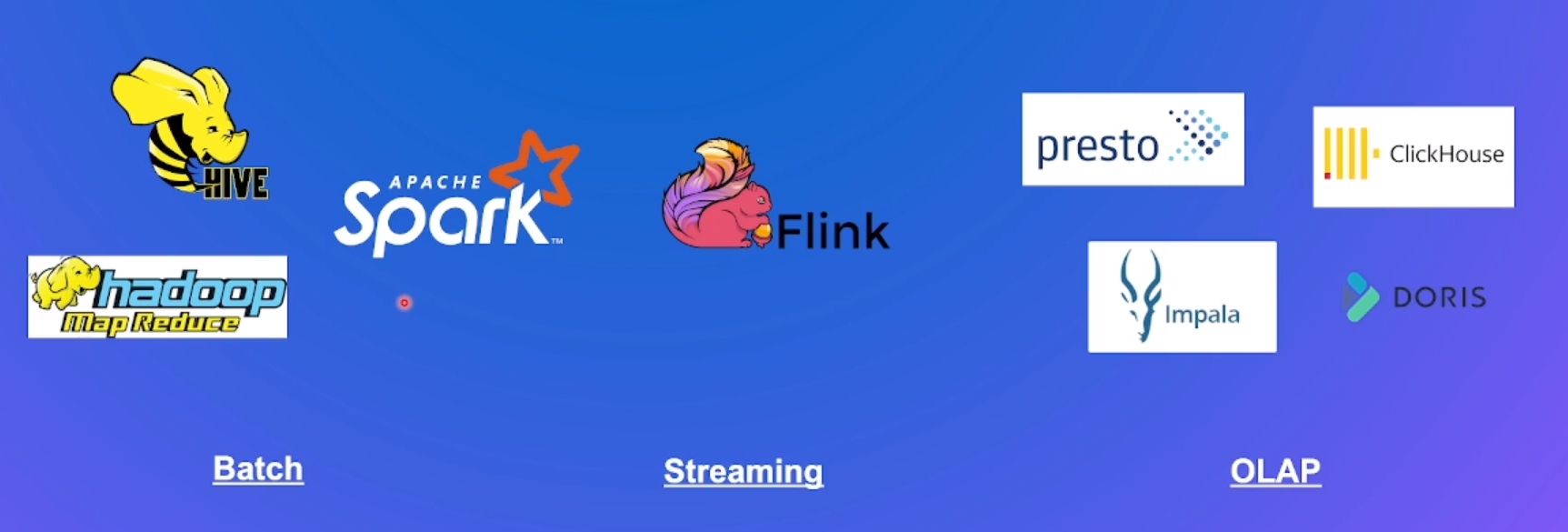
Apache Flink是一个开源的流处理框架,应用于分布式、高性能、高可用的数据流应用程序。可以处理有限数据流和无限数据,即能够处理有边界和无边界的数据流。无边界的数据流就是真正意义上的流数据,所以Flink是支持流计算的。有边界的数据流就是批数据,所以也支持批处理的。不过Flink在流处理上的应用比在批处理上的应用更加广泛,统一批处理和流处理也是Flink目标之一。Flink可以部署在各种集群环境,可以对各种大小规模的数据进行快速计算。
OLAP (OnLine Analytical Processing) 对业务数据执行多维分析,并提供复杂计算,趋势分析和复杂数据建模的能力。是许多商务智能(BI)应用程序背后的技术。现如今OLAP已经发展为基于数据库通过SQL对外提供分析能力

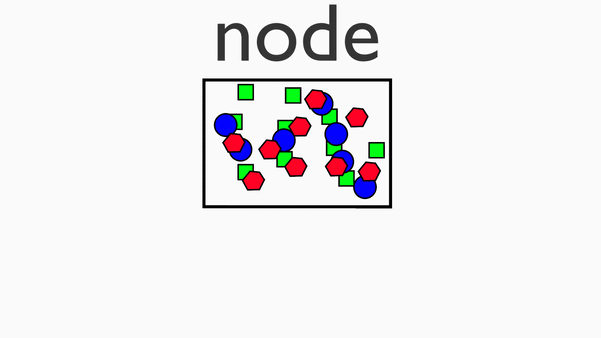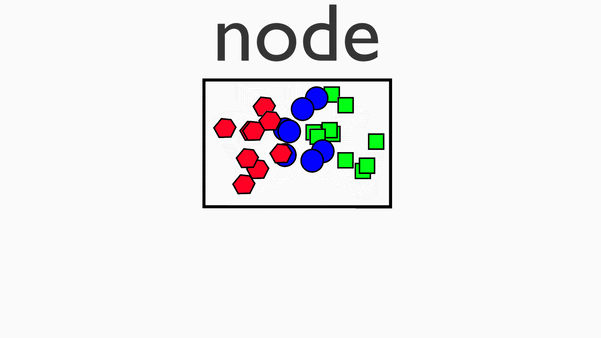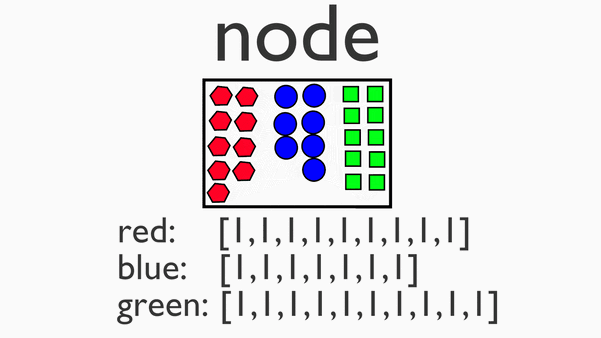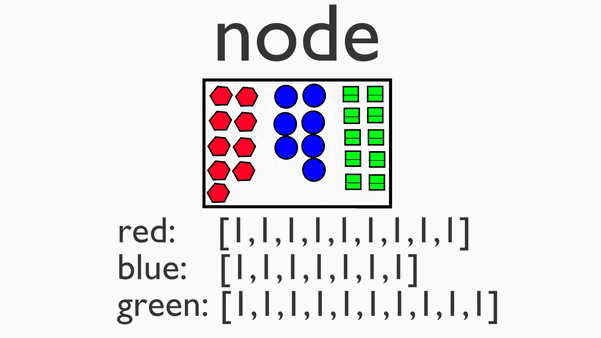
单机上,针对一小块数据的计算过程
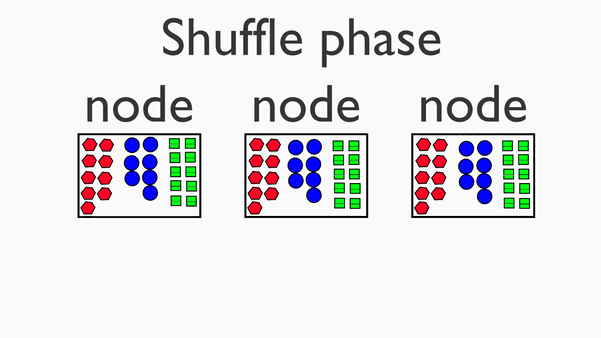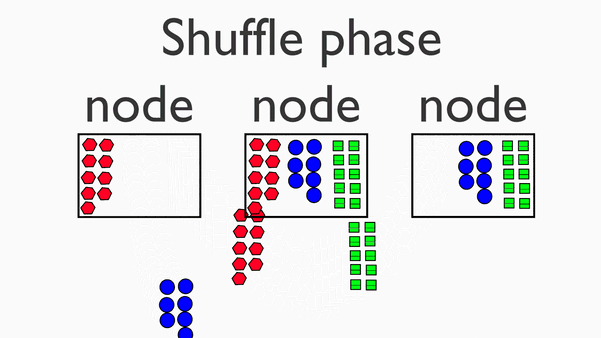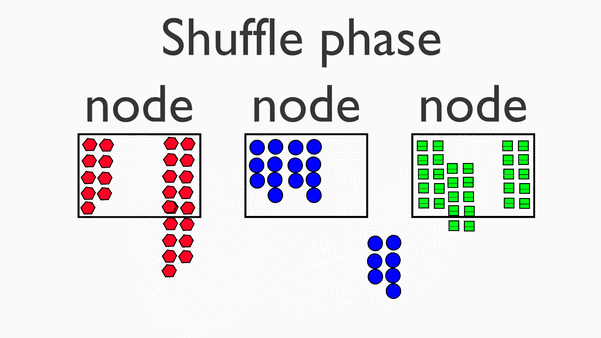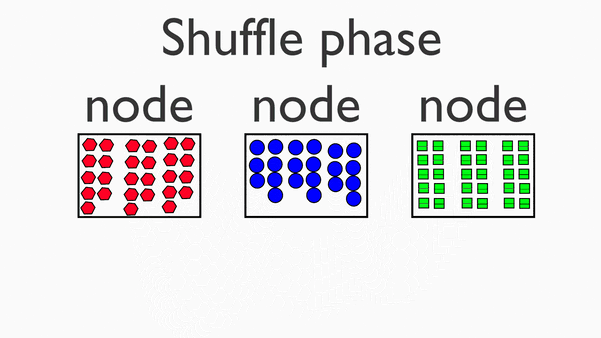
在map阶段的基础上,进行数据移动,为后续的reduce阶段做准备。
数据价值:实时性越高,数据价值越高
| 特性 | 批式计算 | 流式计算 |
|---|---|---|
| 数据存储 | HDFS、Hive | Kafka、Pulsar |
| 数据时效性 | 天级别 | 分钟级别 |
| 准确性 | 精准 | 精准和时效性之间取舍 |
| 经典计算引擎 | Hive、Spark、Flink | Flink |
| 计算模型 | Exactly-Once | At Least Once/Exactly Once |
| 资源模型 | 定时调度 | 长期持有 |
| 主要场景 | 离线天级别数据报表 | 实时数仓、实时营销、实时风控 |